 组会思路
组会思路
# 1、为什么要使用自监督学习呢?
人工设计的标签可能不是最优的
充分利用未标记样本
探索人类是如何学习的
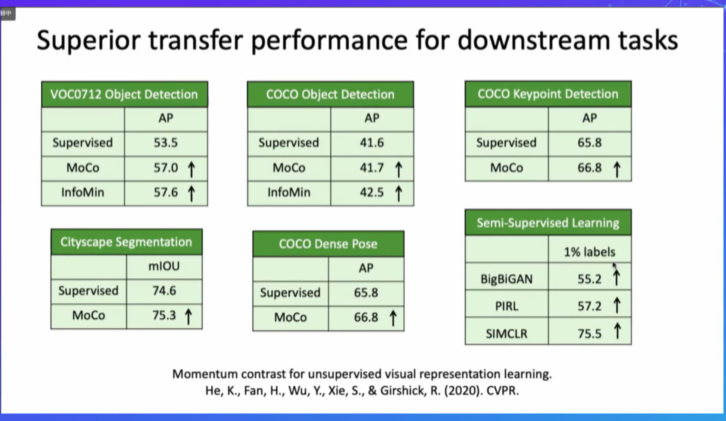
# 2、为什么无监督的pretraining > Supervised pretraining?
迁移学习主要迁移的是底层的特征,而不是高层的语义信息
无监督模型可以保留更多的空间关系,有监督学习会丢失一些空间信息
# 3、基于生成模型的方法(Generative Methods)
- BigBiGAN:ImageNet top1: 56.6%
- Image GPT: 69.0%
# 4、视频上的自监督学习
- Shuffle and Learn:时序正确和错误的二分类
- SpeedNet:视频速度正常和加速的二分类
- 视频自监督的提升空间还比较大
# 5、多模态上的自监督学习
- 声音可以监督视觉的学习:牛的叫声大致相同
# 6、未来的展望
- 为下游任务设计更加好的预训练模型
- 多模态的自监督预训练以及应用
- 设计更加巧妙的策略去自动地搜集更有用的data/label(主动学习?)
什么是 linear protocol?
为了克服基本的OOD和泛化问题,尽管许多工作专注于为神经网络设计新的体系结构,但另一个简单而有效的解决方案是扩大训练数据集以使多个样本“分布内”。但是,事实是,尽管在这个大数据时代中有大量未标记的Web数据可用,但是带有人工标记的高质量数据可能会非常昂贵。例如,数据标签公司Scale.ai3对图像分割标签收取每张图像$ 6.4的费用。包含10k +高质量样本的图像细分数据集可能需要花费一百万美元。
生成式的:训练编码器将输入的信息编码为明确的向量z,并解码器从z重建x(例如,完形填空测试,图形生成)
基于对比:训练编码器对输入信号编码到显式向量z,以测量相似度(例如,互信息最大化,实例区分)
它们的主要区别在于模型架构和目标。图2显示了详细的概念比较。 4.它们的体系结构可以统一为两个通用组件:生成器和鉴别器,并且生成器可以进一步分解为编码器和解码器。不同的是:1)对于潜在的分布z:在生成和对比方法中,它们是显式的,并且经常被下游任务利用; 2)对于判别器:生成器方法没有判别器,而GAN和对比法则具有判别器。对比判别器(例如,具有2-3层的多层感知器)的参数要比GAN少(例如,标准ResNet [53])。3)出于目标:生成方法使用重构损失,对比方法使用对比相似性度量(例如InfoNCE),生成对比方法将分布差异作为损失(例如,JS散度,Wasserstein距离)。与下游任务相关的经过适当设计的训练目标可以将我们随机初始化的模型转变为出色的预训练特征提取器。例如,对比学习被发现对于几乎所有视觉分类任务都是有用的。这可能是因为对比对象正在建模不同图像实例之间的类不变性。对比损失使包含相同对象类别的图像更加相似。它使包含不同类的对象不太相似,基本上符合下游图像分类,对象检测和其他基于分类的任务。自我监督学习的艺术主要在于为未标记的数据定义适当的目标。
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12