 A Tutorial of Transformers
A Tutorial of Transformers
# A Tutorial of Transformers
# 1、前言
语言表示学习指的是如何表示语言的语义,发展历程从知识图谱->分布式表示。表示学习将词映射为一个向量,这种向量一般被称为词嵌入(Embeddings)
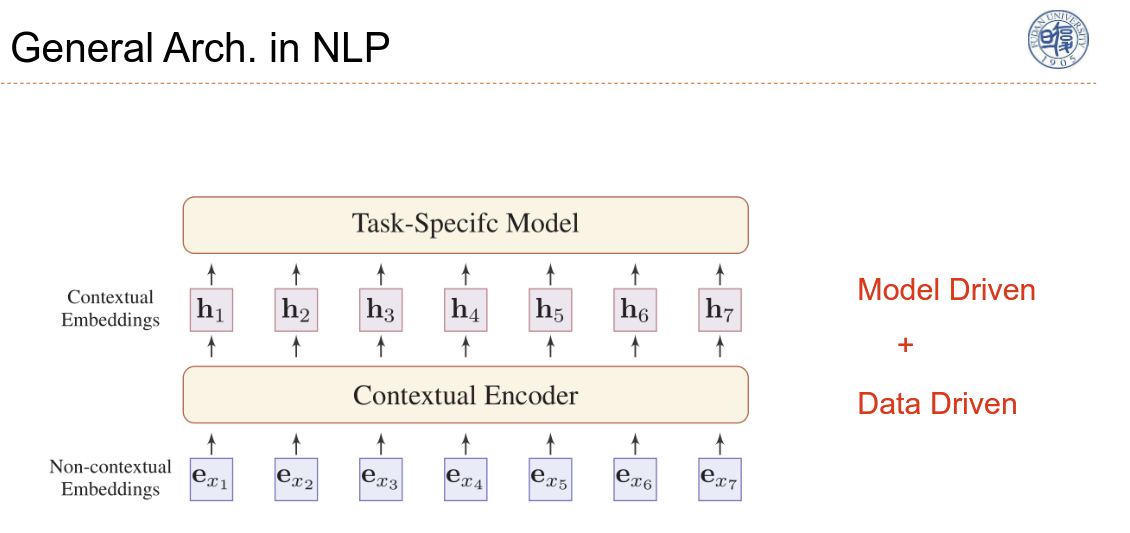
上下文编码器将上下文编码进词嵌入中,更准确地去体现词的语义。上下文编码器即为 Model 架构的设计,是模型驱动的,而如何基于数据将特征提取得更好,是数据驱动的
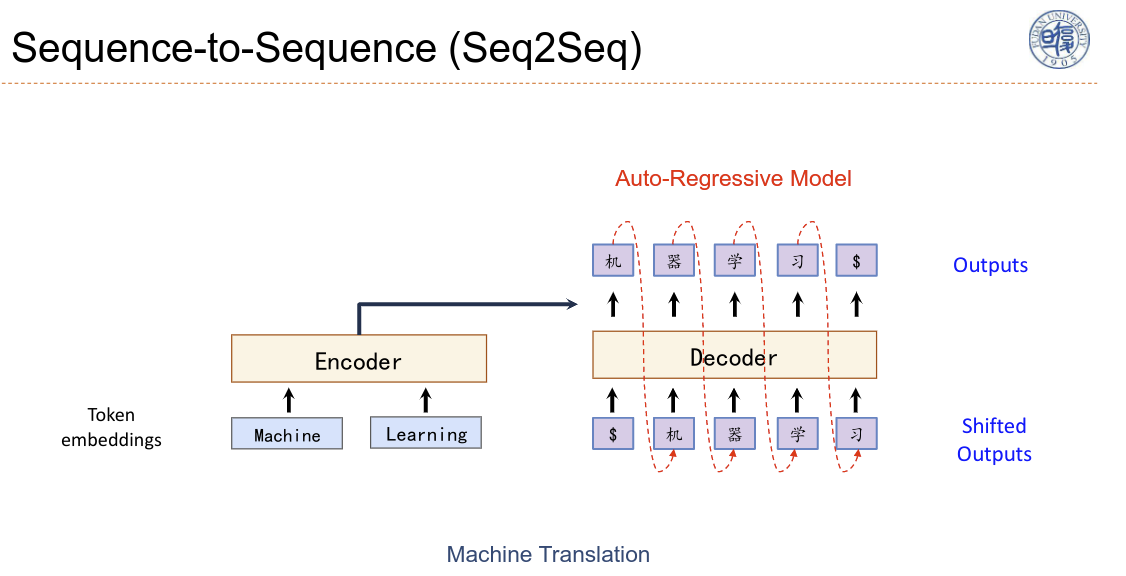
这里是机器翻译的一个例子,Decoder是一个自回归模型
# 2、如何建立远距离的依赖关系?
全连接是一个非常简单的方式,但是计算量大以及不够灵活
注意力机制,主要过程有两步
- 计算注意力分布,并做归一化
- 对所有的信息进行加权,根据这个注意力分布做输入做期望
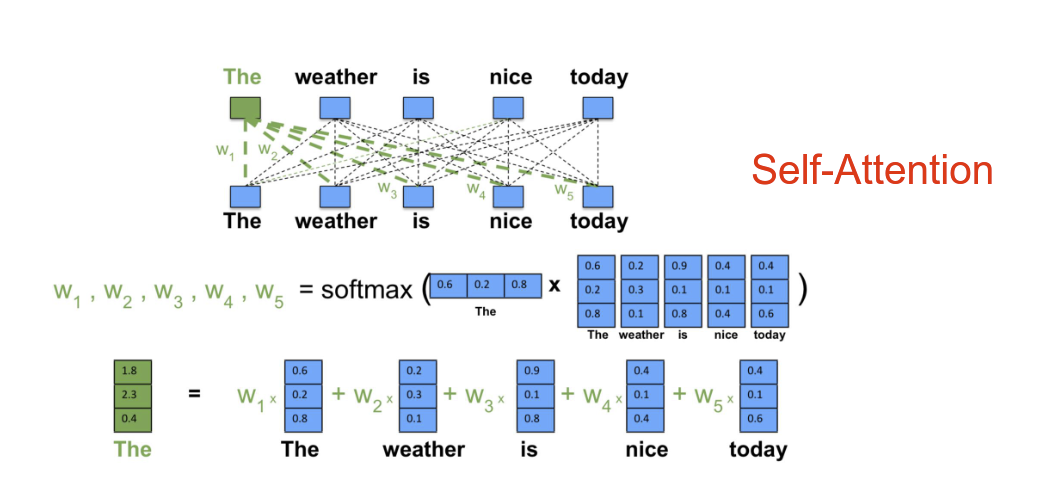
如何建模词语之间的依赖关系?上图是一个例子,也被成为 self-attention
- 如果我们要查询The 的注意力
- “The” 这个单词的 Embedding作为q,句子中其他所有词作为v,
- 将 q 和 v 计算相似度,归一化之后得到权重
- 最终 “The” 便可以由其他词表示
# 3、建模 Query-Key-Value(QKV)Model
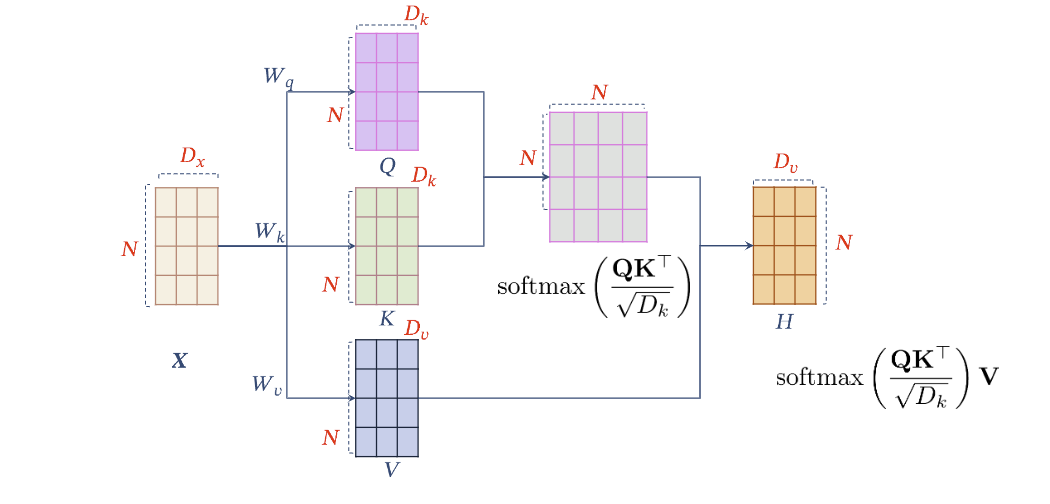
QKV 有三个可学习的矩阵,使得其模型容量更大,可学习能力也更强
# 4、Multi-head Self-Attention
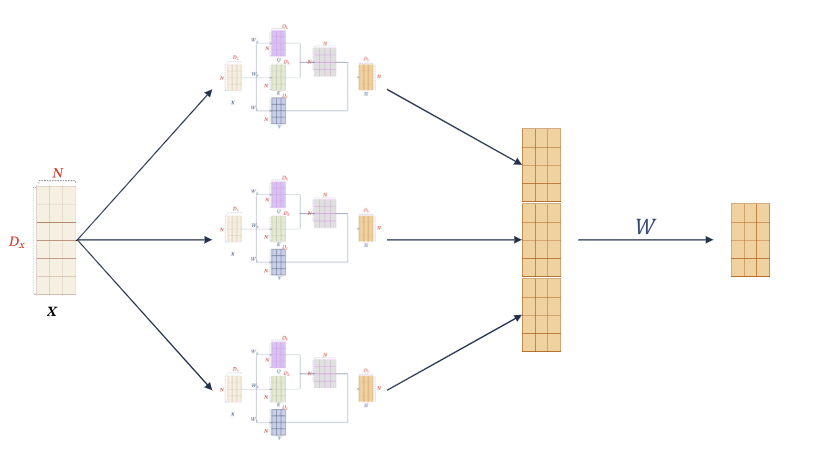
在多个高维空间中去建模他们的关系,类似于卷积中的多通道
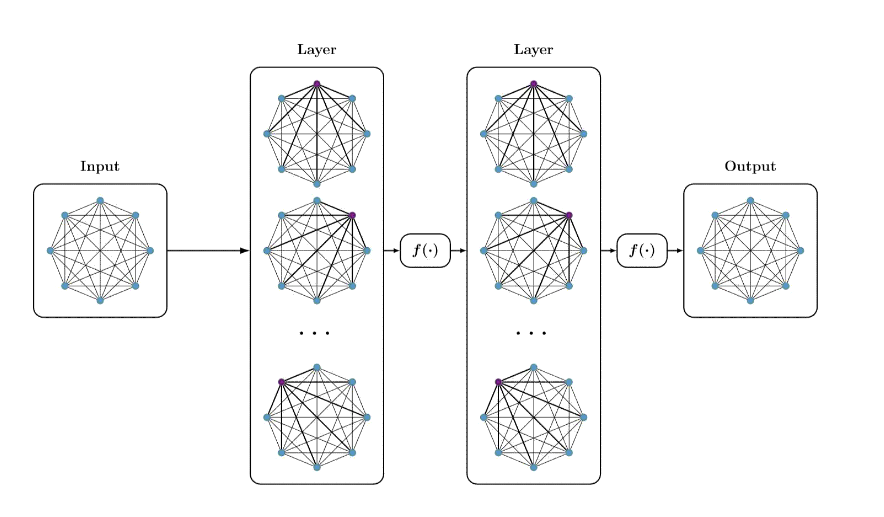
# 5、Multi-Layer Self-Attention
# 6、Transformer
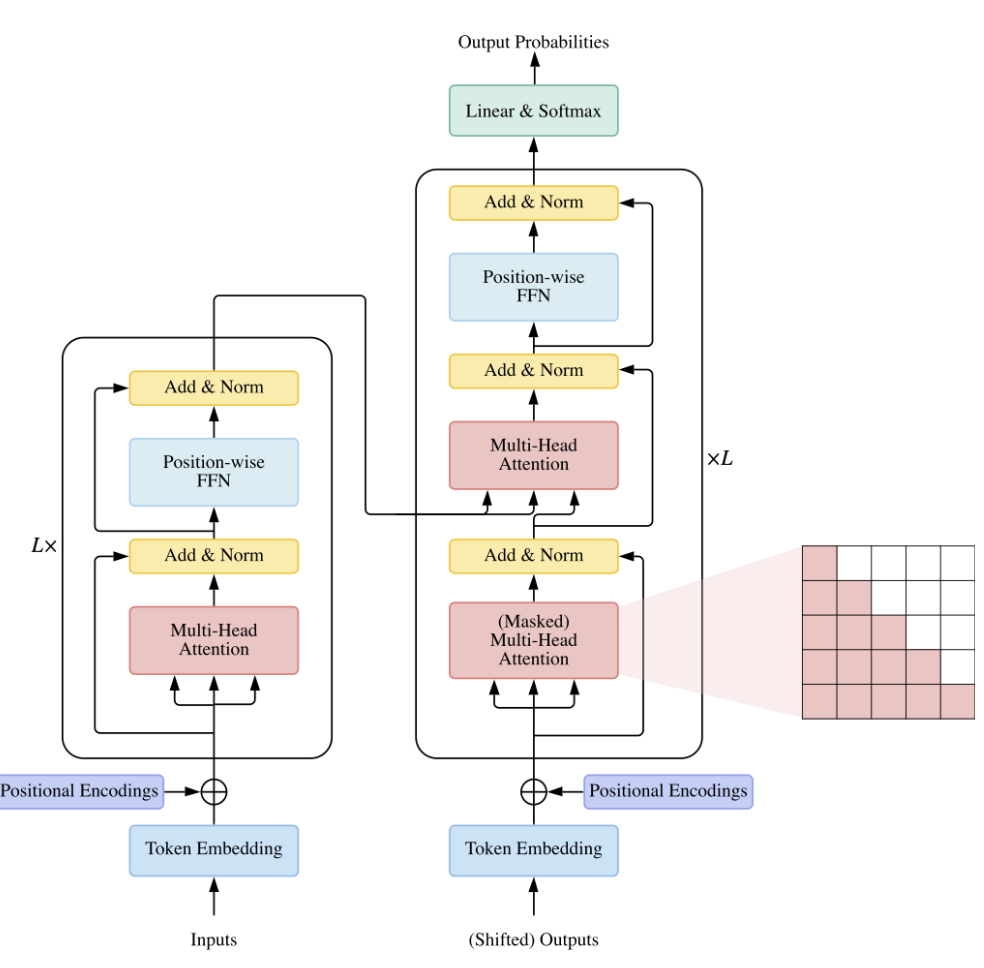
关键模块:Self-Attention
改进 Self-Attention
- 传统Self-Attention只和内容相关,和位置没有关系,加入位置信息的编码
- Layer Normalization
- Skip connection
- Position-wise FFN
# 参考资料:
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017. arXiv link (opens new window)
- Lin, Tianyang, et al. "A Survey of Transformers." arXiv preprint arXiv:2106.04554 (2021). arXiv link (opens new window)
上次更新: 2021/09/26, 00:09:41
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12