 few-shot learning 竞赛学习-2
few-shot learning 竞赛学习-2
# Few-shot Learning 竞赛学习-2
经过初步的调研和思考,觉得 Metric Learning 这种范式比较适合我快速上手
最终决定使用目前 image clustering 任务 SOTA 结果的 SPICE 来做本次任务
SPICE 算法链接:https://paperswithcode.com/paper/spice-semantic-pseudo-labeling-for-image
SPICE 算法流程 (opens new window)
- 首先使用 MoCov2 算法无监督训练训 1000 个 epoch
- 使用预训练模型来提取 Embedding feature
- 训练 SPICE-Self
- 来区分 reliable images
- 训练 SPICE-Semi
下面分步骤来解释下代码
# 1、使用 MoCov2 算法无监督训练训 1000 个 epoch
这里作者使用了 kaiming 开源的 moco代码 (opens new window) 进行训练,稍微修改下即可,训练脚本如下:
python train_moco.py --data_type prcv2021 --data ./datasets/prcv2021 --img_size 96 --save_folder ./results/prcv2021/moco --arch clusterresnet --start_epoch 0 --epochs 1000 --gpu 0 --resume ./results/prcv2021/moco/checkpoint_last.pth.tar --mlp --moco-t 0.2 --aug_plus --cos
# 2、使用预训练模型来提取 Embedding feature
对所有训练样本(49900张图像)提取Embedding feature,核心代码如下:
# create model
model_sim = build_model_sim(cfg.model_sim)
# Load similarity model
if cfg.model_sim.pretrained is not None:
load_model_weights(model_sim, cfg.model_sim.pretrained, cfg.model_sim.model_type)
# Evalidation status
model_sim.eval()
# Define dataloader
dataset_val = build_dataset(cfg.data_test)
val_loader = torch.utils.data.DataLoader(dataset_val, batch_size=cfg.batch_size, shuffle=False, num_workers=1)
# Define a AvgPool2d to pooling features
pool = nn.AdaptiveAvgPool2d(1)
feas_sim = []
for _, (images, _, labels, idx) in enumerate(val_loader):
images = images.to(cfg.gpu, non_blocking=True)
print(images.shape)
with torch.no_grad():
feas_sim_i = model_sim(images)
if len(feas_sim_i.shape) == 4:
feas_sim_i = pool(feas_sim_i)
feas_sim_i = torch.flatten(feas_sim_i, start_dim=1)
feas_sim_i = nn.functional.normalize(feas_sim_i, dim=1)
feas_sim.append(feas_sim_i.cpu())
feas_sim = torch.cat(feas_sim, dim=0)
feas_sim = feas_sim.numpy()
np.save("{}/feas_moco_512_l2.npy".format(cfg.results.output_dir), feas_sim)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 3、训练 SPICE-Self

SPICE-Self 的流程如上图所示:
- Unlabeled 经过 Weak 和 Strong 的数据增强,分别输入到上述预训练好的 CNN 中
- Original 分支提取 Embedding,这里可以离线提取,如第二步
- Weak 分支送入 CNN + CLSHead(10个Head),输出的 predicted probabilities 同Original 分支的Embedding 一起生成 Pseudo-Label
- Strong 分支送入 CNN + CLSHead(10个head,与Weak分支共享参数),输出的 predicted probabilities 与Pseudo-Label 一起计算 DS-CE Loss来优化 Head
注:
- 上图的 CNN 和 CLSHead 都是共享参数的
- CNN 是固定参数的,DS-CE Loss 只用来优化 CLSHead
- 训练时训十个 CLSHead,预测时只用性能最优的 Head 推理
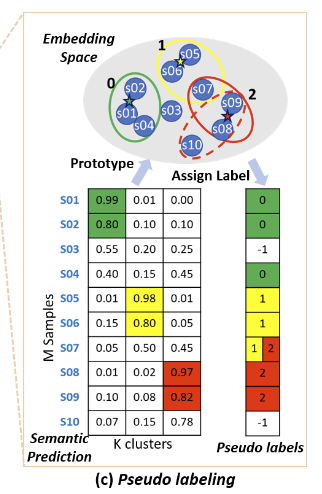
上图是Pseudo labeling 的流程,
- 计算每个样本和 Embedding Space 中 Prototype 的距离
- 卡一个阈值来生成伪标签
# 4、生成 Reliable Samples
对于样本 ,根据 Embedding feature 间的余弦距离挑选 个最近邻样本,所有样本的标签集合记为
计算样本 的局部一致性
- 其实就是计算最近邻样本和自己标签一致的比例
如果 , 则样本 即可被视作 Reliable Samples
将 Reliable Samples 作为已标注样本,剩余的作为未标注样本,由此将该问题转化为半监督问题,送入SPICE-Semi 算法框架中
# 5、训练 SPICE-Semi
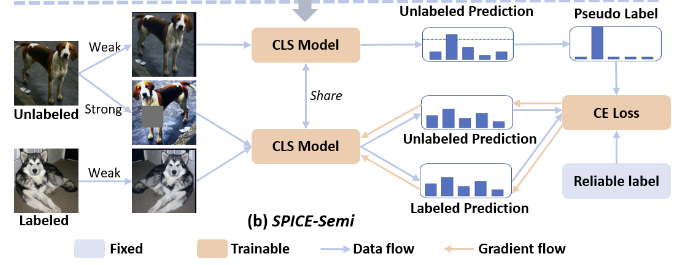
将 Labeled 和 Unlabeled 样本经过 Weak 和 Strong 的数据增强,分别输入到上述预训练好的 CNN 中
Unlabeled Weak 分支输入到 CLS Model 中,生成 Unlabeled Prediction 作为伪标签
Unlabeled Strong 分支输入到 CLS Model 中,生成 Unlabeled Prediction,与伪标签做 CE Loss
labeled Weak 分支输入到 CLS Model 中,生成 Labeled Prediction,和 Reliable label 做 CE Loss
# 6、与正确标签的索引相对应
上述流程训出来的模型聚类效果可能会比较好,但是类别的索引可能会错乱,有多个解决方案
# 7、实验结果
不太行
# 参考资料
- SPICE paper: https://arxiv.org/abs/2103.09382v1
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12