 如何加载数据集
如何加载数据集
# 如何加载数据集
# Cityscapes 数据集
# 类别数量及其所对应的 trainId 以及 color
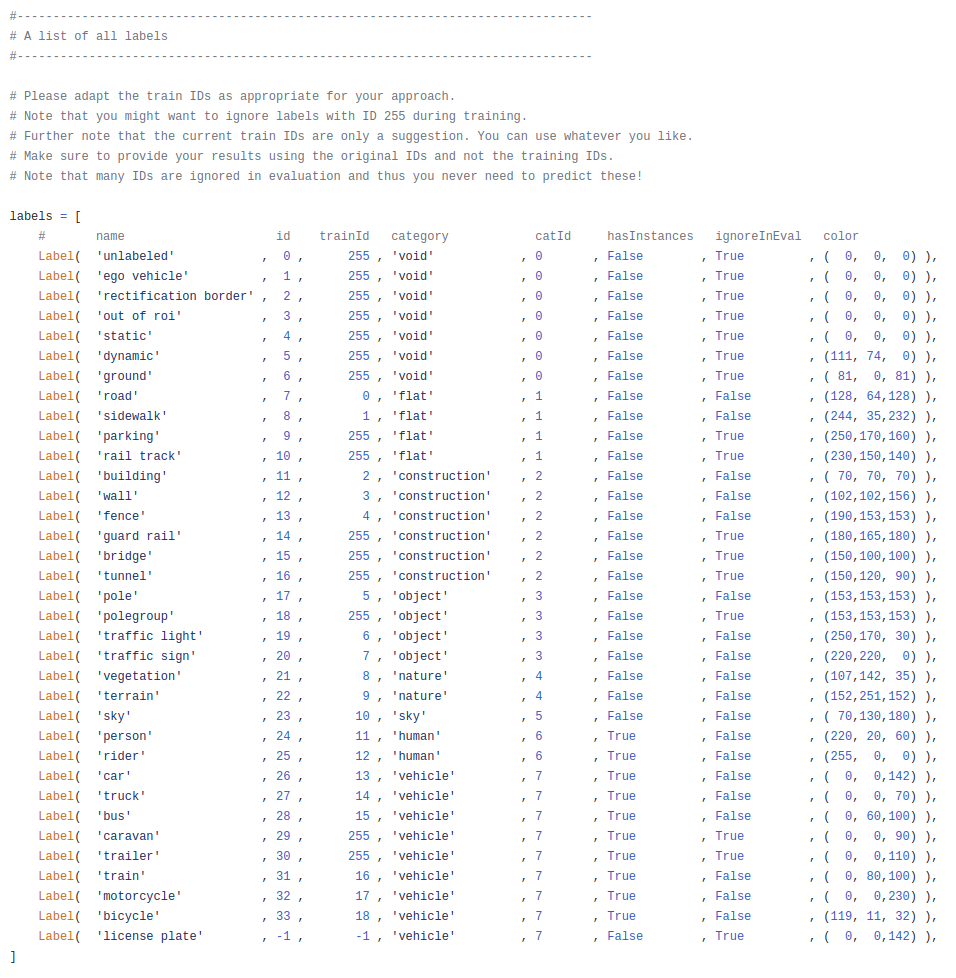
在 官方脚本 (opens new window) 中可以看到标签的情况,截图如上。分为 8 个大类,其中 human 和 vehicle 两大类是拥有实例标签的。此外我们只需关注 ignoreInEval 字段为 False 的类别即可,共 19 类,所以我们在语义分割中对于每个像素都有 20 类输出,还有一个背景类别。并且实际参与训练的类别 id 是 trainId 字段的内容。
# 标签可视化
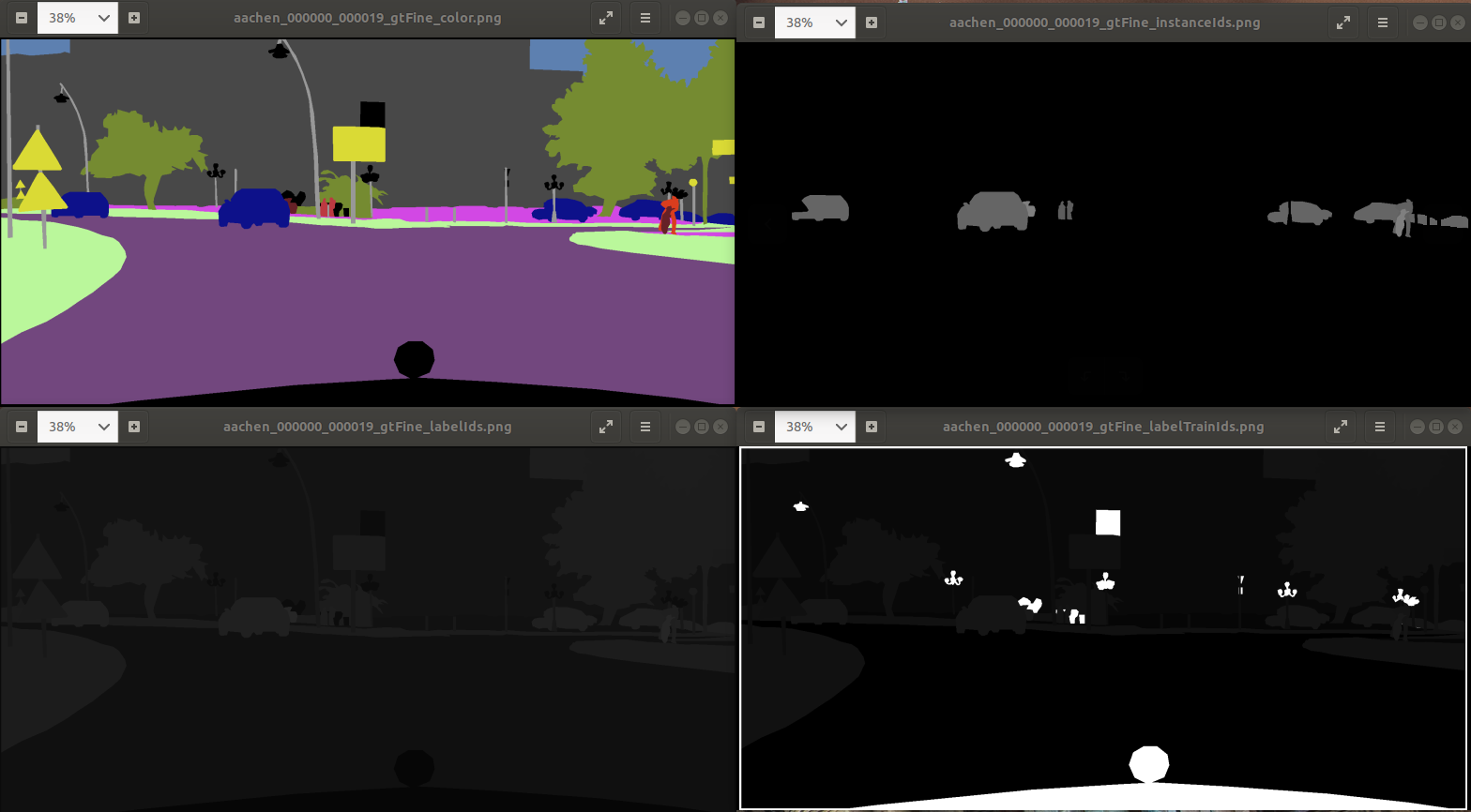
对于每张图像,官方数据集里都对应了四张标注,示例如上。
aachen_000000_000019_gtFine_color.png:彩色标注可视化
aachen_000000_000019_gtFine_instanceIds.png:标出
human以及vehicle两个大类的实例 idaachen_000000_000019_gtFine_labelIds.png:按照 labelId 来做可视化
aachen_000000_000019_gtFine_labelTrainIds.png:按照 TrainId 来做可视化
官方脚本:https://github.com/mcordts/cityscapesScripts
# 如何构建 Cityscapes 数据集的 Dataloader
# 使用 PyTorch 的官方接口
import torchvision
import numpy as np
root = r'./Cityscapes/'
# target_type = ['instance', 'semantic', 'color', 'polygon']
target_type = 'instance'
cityscapes_dataset = torchvision.datasets.Cityscapes(root, split='train', mode='fine', target_type=target_type, transform=None, target_transform=None)
2
3
4
5
6
7
8
9
10
我们可以写如上的代码使用 PyTorch 官方提供的 Dataset 接口直接使用,但这样我觉得不够灵活,所以我决定还是自己实现 Dataloader。
# 手动实现
import os
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import mmcv
import glob
class cityscapesDataset(Dataset):
def __init__(self, root, split='train', img_size=(1024, 512), img_norm=True, gt_type='gtCoarse'):
super(cityscapesDataset, self).__init__()
self.name_dataset = 'Cityscapes'
self.num_classes = 19
self.colormap = {
0: (0, 0, 0), # unlabeled
1: (0, 0, 0), # ego vehicle
2: (0, 0, 0), # rectification border
3: (0, 0, 0), # out of roi
4: (0, 0, 0), # static
5: (0, 0, 0), # dynamic
6: (0, 0, 0), # ground
7: (128, 64, 128), # road
8: (244, 35, 232), # sidewalk
9: (0, 0, 0), # parking
10: (0, 0, 0), # rail track
11: (70, 70, 70), # building
12: (102, 102, 156), # wall
13: (190, 153, 153), # fence
14: (0, 0, 0), # guard rail
15: (0, 0, 0), # bridge
16: (0, 0, 0), # tunnel
17: (153, 153, 153), # pole
18: (0, 0, 0), # polegroup
19: (250, 170, 30), # traffic light
20: (220, 220, 0), # traffic sign
21: (107, 142, 35), # vegetation
22: (152, 251, 152), # terrain
23: (0, 130, 180), # sky
24: (220, 20, 60), # person
25: (255, 0, 0), # rider
26: (0, 0, 142), # car
27: (0, 0, 70), # truck
28: (0, 60, 100), # bus
29: (0, 0, 0), # caravan
30: (0, 0, 0), # trailer
31: (0, 80, 100), # train
32: (0, 0, 230), # motorcycle
33: (119, 11, 32), # bicycle
-1: (0, 0, 0) # license plate
# 5: (111, 74, 0), # dynamic
# 6: (81, 0, 81), # ground
# 9: (250, 170, 160), # parking
# 10: (230, 150, 140), # rail track
# 14: (180, 165, 180), # guard rail
# 15: (150, 100, 100), # bridge
# 16: (150, 120, 90), # tunnel
# 18: (153, 153, 153), # polegroup
# 29: (0, 0, 90), # caravan
# 30: (0, 0, 110), # trailer
}
self.labels = {
0: 'unlabeled',
1: 'ego vehicle',
2: 'rectification border',
3: 'out of roi',
4: 'static',
5: 'dynamic',
6: 'ground',
7: 'road',
8: 'sidewalk',
9: 'parking',
10: 'rail track',
11: 'building',
12: 'wall',
13: 'fence',
14: 'guard rail',
15: 'bridge',
16: 'tunnel',
17: 'pole',
18: 'polegroup',
19: 'traffic light',
20: 'traffic sign',
21: 'vegetation',
22: 'terrain',
23: 'sky',
24: 'person',
25: 'rider',
26: 'car',
27: 'truck',
28: 'bus',
29: 'caravan',
30: 'trailer',
31: 'train',
32: 'motorcycle',
33: 'bicycle',
-1: 'license plate'
}
self.trainId = [7, 8, 11, 12, 13, 17, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 31, 32, 33]
self.ignoreId = [0, 1, 2, 3, 4, 5, 6, 9, 10, 14, 15, 16, 18, 29, 30, -1]
self.classmap = dict(zip(self.trainId, range(self.num_classes)))
self.split = split
self.img_size = img_size
self.img_norm = img_norm
self.ignore_index = 250
self.gt_type = gt_type
self.root = root
self.images_base = os.path.join(self.root, "leftImg8bit", self.split)
self.annotations_base = os.path.join(self.root, self.gt_type, self.split)
self.files = {}
self.files[self.split] = glob.glob(os.path.join(self.images_base, '*/*.png'))
print('debug')
def __getitem__(self, index):
img_path = self.files[self.split][index].rstrip()
label_path = os.path.join(
self.annotations_base,
img_path.split(os.sep)[-2],
os.path.basename(img_path)[:-15] + f"{self.gt_type}_labelIds.png"
)
img = mmcv.imread(img_path, channel_order='rgb')
label = mmcv.imread(label_path, flag='grayscale')
label = self.encode_segmap(label)
# transform & augmentations
img, label = self.transform(img, label)
return img, label
def __len__(self):
return len(self.files[self.split])
def decode_segmap(self, mask):
r = mask.copy()
g = mask.copy()
b = mask.copy()
for cls in range(self.num_classes):
color_cls = self.trainId[cls]
r[mask == cls] = self.colormap[color_cls][0]
g[mask == cls] = self.colormap[color_cls][1]
b[mask == cls] = self.colormap[color_cls][2]
rgb = np.zeros((mask.shape[0], mask.shape[1], 3))
rgb[:, :, 0] = b / 255.0
rgb[:, :, 1] = g / 255.0
rgb[:, :, 2] = r / 255.0
return rgb
def encode_segmap(self, mask):
for ignorecls in self.ignoreId:
mask[mask == ignorecls] = self.ignore_index
for traincls in self.trainId:
mask[mask == traincls] = self.classmap[traincls]
return mask
def transform(self, img, label):
img = mmcv.imresize(img, (self.img_size[0], self.img_size[1]))
img = img.astype(np.float64)
if self.img_norm:
img = img.astype(float) / 255.0
classes = np.unique(label)
label = label.astype(float)
label = mmcv.imresize(label, (self.img_size[0], self.img_size[1]), interpolation='nearest')
label = label.astype(int)
if not np.all(classes == np.unique(label)):
print("WARN: resizing labels yielded fewer classes")
if not np.all(np.unique(label[label != self.ignore_index]) < self.num_classes):
print("after det", classes, np.unique(label))
raise ValueError("Segmentation map contained invalid class values")
img = torch.from_numpy(img).float()
label = torch.from_numpy(label).long()
return img, label
# dataloader test
if __name__ == '__main__':
train_dataset = cityscapesDataset(root='/home/muyun99/data/dataset/cityscapes', split='train', img_size=(1024, 512), img_norm=True, gt_type='gtFine')
train_dataloader = DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=8, pin_memory=True)
print(len(train_dataset))
for i, batch in enumerate(train_dataloader):
imgs, masks = batch
if i == 0:
print("单个img的size: ", imgs.shape)
print("单个mask的size: ", masks.shape)
img = imgs[0].numpy()
mask = masks[0].numpy()
mask = train_dataset.decode_segmap(mask)
mmcv.imshow(img, wait_time=1000)
mmcv.imshow(mask, wait_time=1000)
# break
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
# 参考资料
https://github.com/meetshah1995/pytorch-semseg/blob/master/ptsemseg/loader/cityscapes_loader.py
https://github.com/Tramac/awesome-semantic-segmentation-pytorch/blob/master/core/data/dataloader/cityscapes.py
https://github.com/fvisin/dataset_loaders/blob/master/dataset_loaders/images/cityscapes.py
1、修改 ignore_id
2、将 ignore_id 的类别修改为 255
3、计算 loss 的时候除去255的类别
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12