 VALSE Webinar 20-02 元学习与小样本学习
VALSE Webinar 20-02 元学习与小样本学习
# VALSE Webinar 20-02 元学习与小样本学习
# 01、Siyuan Qiao JHU
# Few-Shot Image Recognition by Predictiong Parameters from Activations (CVPR 2018)
m-shot n-way image recognition
- m-shot: each new class has m training images
- n-way: predict the class of test images from n classes
Few-shot + large-scale image recognition
- pre-training on large-scale datasets(black) and few-shot adaptation to new classes(green).
- 有点像 open-set 问题设置
两个数据集:Few-shot 和
目标:在两个数据集上效果都比较优异
两个小tricks:
Multi-View:
集成学习, 学两个映射
# 02、Deyu Meng XJTU
鲁棒深度学习与元学习
深度学习:标注质量很高的数据集,但是现实情况中数据是存在偏差的(Data bias),例如小样本、弱监督、标签带噪
- Label Noise:标签是带有噪声的
- Data Noise:数据本身带有噪声的
- Class imbalance:类别不平衡
鲁棒学习
- 设计不同的鲁棒优化目标,例如鲁棒的损失函数
- 化腐朽为神奇:从质量很差的数据集中依然能抽取出我们想要的信息
- 损失函数
- Label Noise
- Generalized CE (NeurIPS 2018)
- Symmetric CE (ICCV 2019)
- Bi-Tempered logistic loss (NeurIPS 2019)
- Polynomial Softweighting loss (AAAI 2015)
- Focal loss (TPAMI 2018):class imbalance
- CT loss (TMI 2018): data noise
- 问题:需要设置超参数,非凸优化
- Label Noise
元学习
验证数据集和训练数据集的区别
- 验证数据集用于超参数的调整,训练数据集用于分类器参数的学习
设计一个 Meta loss
- Optimization instead of search
- Intelligent instead of heuristic (partially)
Sample Reweighting methods
- Self-paced
- Linear weighting
- Focal Loss
- Hard example mining:采样
- Prediction variance
对样本的损失前加一个权重,放大/缩小一些样本损失
- 出现了截然不同的两种加权策略
- 误差大权重小,误差小权重大:认为误差大的样本是噪声样本(label noise)
- 误差大权重大,误差小权重小:认为误差大的样本是难样本(class imbalance $ ohem)
- 使用 Meta Learning,将样本权重当做超参数去学出来
- MentorNet:V太多了,不能有效地利用前序信息,训练起来不稳定
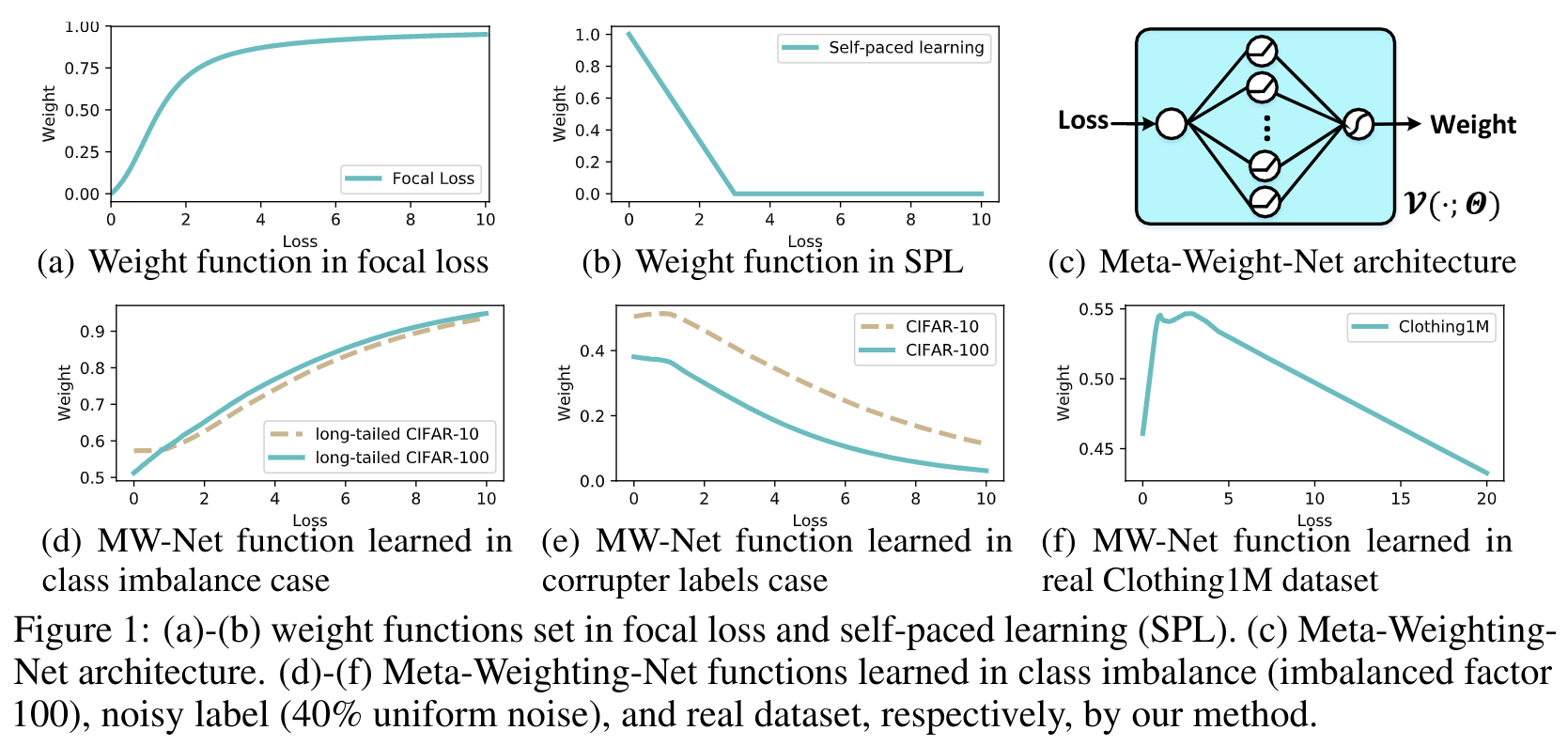
- Meng组的改进:Meta-Weight-Net
- Meta-Weight-Net: Learning an Explict Mapping for Sample Weighting. (NeuIPS 2019)
- 将V变成一个函数,输入是Loss,输出是weight,函数希望既能够拟合单调递增又能够拟合单调递减,所以就用MLP来实现
- 从下图中可以看出,学的确实不错
- 出现了截然不同的两种加权策略
上次更新: 2021/09/26, 00:09:41
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12