 图像检索orReID 竞赛的 Tricks
图像检索orReID 竞赛的 Tricks
# Bag of Tricks and A Strong Baseline for Deep Person Re-identification
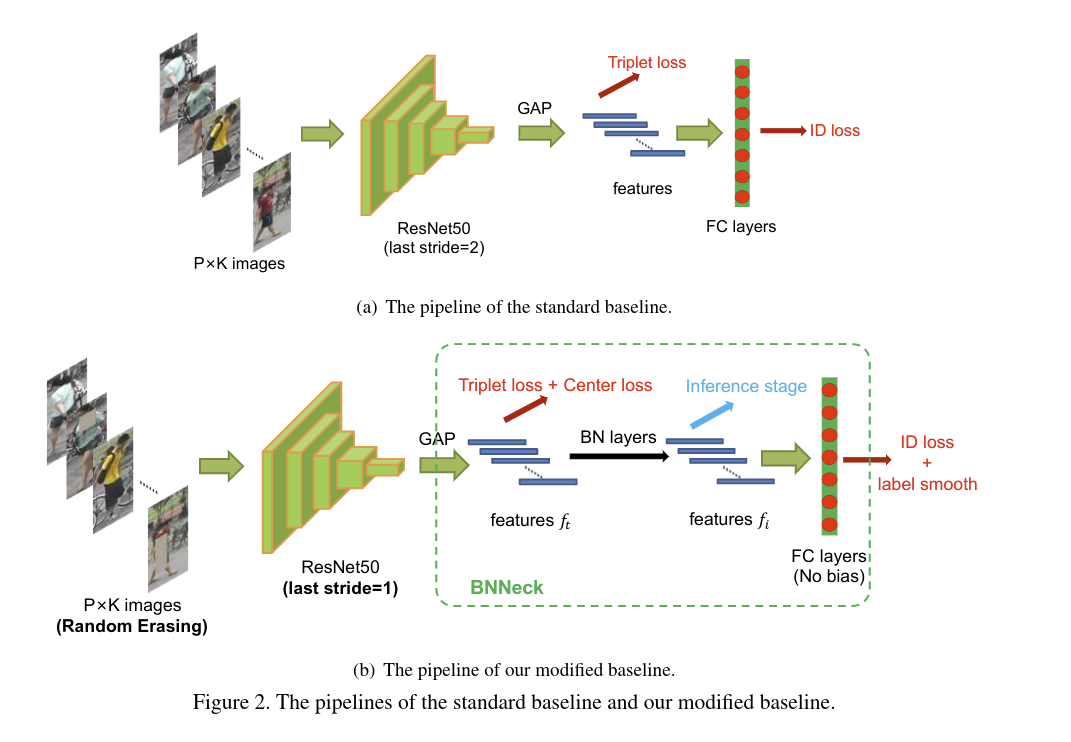
# 01、标准的 Baseline(github (opens new window))
- 使用 ResNet50 ,加载 ImageNet 上的预训练参数,改变全连接层的维度为 N,N代表训练集中实体的数量
- 随机采样 P 个实体以及每个人的 K 张图像来构建训练 batch,最终的 batch size B = PxK,论文中,将 P 设置为16,K设置为4,也就是说每个 batch 采样 16 个人,每个人采样 4 张图像(√)
- 每张图像 resize 成 256 x 128,用零值 padding 了10像素,然后随机 crop 到256 x 128(√)
- 每张图像以 0.5 的概率水平翻转(√)
- 每张图像以 32-bit 的 [0,1] 之间的浮点数表示,利用ImageNet的均值和标准差来做归一化(√)
- 模型输出 ReID 的特征 f 以及 ID 预测概率 p(√)
- ReID 特征 f 用于计算 triplet loss,ID 预测概率 p 用于计算交叉熵,triplet loss 的 margin 设置为 0.3
- Adam 优化器,初始的学习率设置为 0.00035 ,40th 和 70th 分别变为原来的0.1,一共有 120 个训练 epoch(√)
# 02、训练技巧
大多数训练技巧不用改变模型结构
# 2.1 Warmup Le Rate
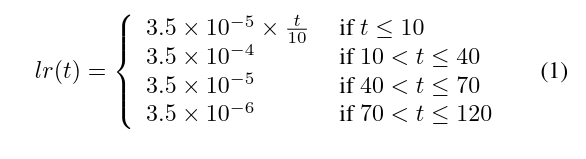
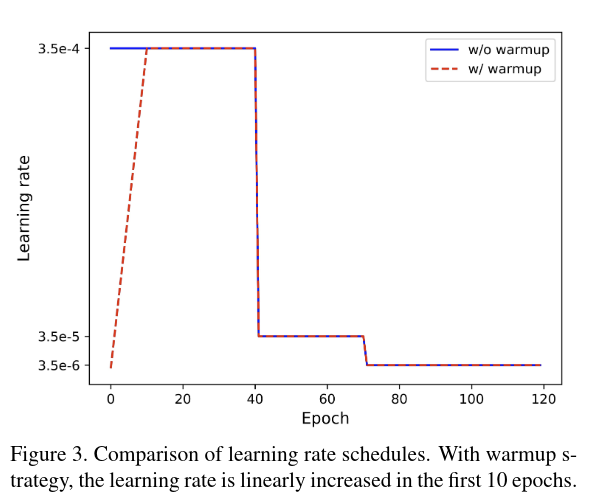
学习率非常关键,Warmup 能够提升网络性能,
# 2.2 Random Erasing Augmentation
在行人的 ReID 中常常出现遮挡问题,应用 Random Erasing 的概率是 ,会选择一个方形区域 ( ),用随机值擦除其原值,
表示原图, 表示擦除的区域, 和 分别代表原图尺寸和擦除区域的尺寸, 表示擦除区域比例。
一般是随机在 和 之间变动,本文的设置如下:
# 2.3 Label Smoothing
ID Embedding Network 是行人 ReID 中一个基础的 baseline,因为常用的交叉熵损失是计算输出的ID label 与真实 ID label 之间的损失,称之为 ID loss,其使用 Label Smoothing 是有帮助的
是一个小的常量来鼓励模型对训练集更加不自信,本文设置其为 0.1,当训练集不是很大时,LS 可以显著提升模型性能
# 2.4 Last Stride
将 last stride 从 2 改为 1,可以提升特征图的尺寸,以 ResNet 为例,可以从 8x4 得到 16x8 的特征图,更高的空间分辨率可以带来十分显著的改进
# 2.5 BNN Neck
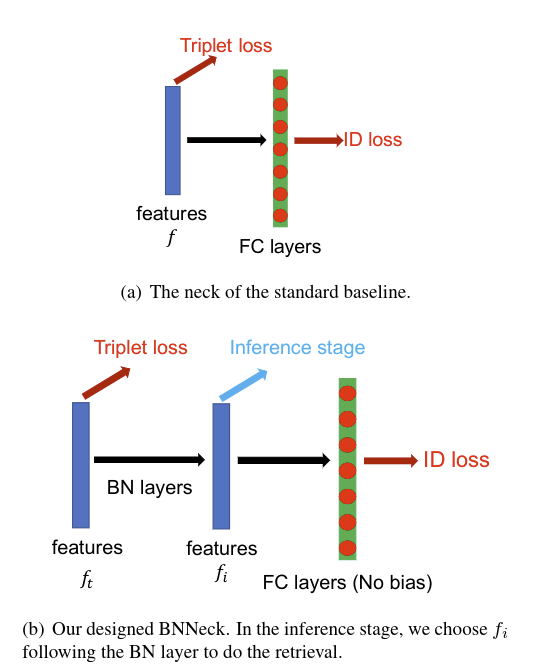
常用的 ReID 模型都会结合 ID loss 以及 triplet loss 来训练,在标准的 baseline 中,ID loss 和 triplet loss 约束同一个特征 f,但是这两个损失的目标在 embedding 空间上是不一致的
如上图所示,Triplet loss 用于约束 feature ,ID loss 用于约束 ,最终在推理的时候使用
BNN neck 只在 后面加了一层 BN 层,余弦距离比欧氏距离更好
# 2.6 Center loss
Triplet Loss 如上式, 和 分别表示正样本对和负样本对的特征距离, 表示 triplet loss 的 margin ,本文设置为 0.3。Triplet loss 只考虑了特征距离之间的不同,忽略了其绝对值的大小
L_C=\frac{1}{2}\sum_\limits{j=1}^{B}||f_{t_j}−c_{y_j}||_2^2
上图是 Center loss,其中 是 mini-batch 中第 个图像的标签。 表示深度特征的第 i 个类别中心。 是批量大小的数量。该公式有效地表征了类内变化。最小化中心损失会增加类内的紧凑性。
我们的模型总共包含了上式三个损失,其中 设置为 0.0005
# 2.7 Reranking
# 03、实验分析
# 3.1 每个 Trick 的有效性
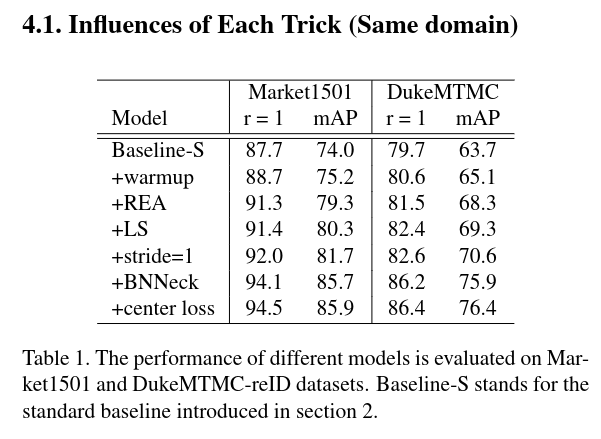
# 3.2 BNN Neck 的有效性
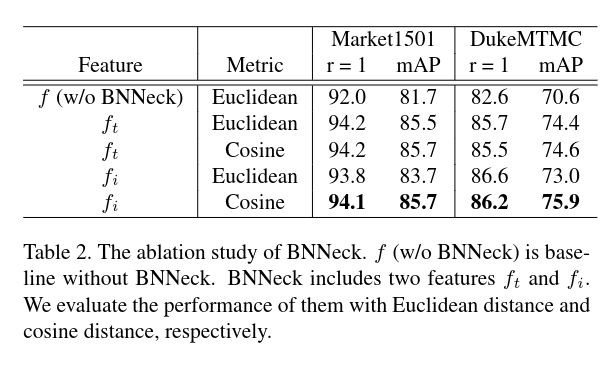
# 3.3 不同 batch_size 的有效性
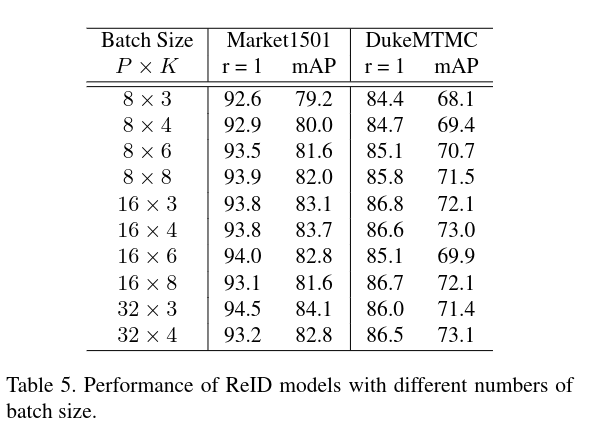
# 3.4 不同 Image Size 的影响
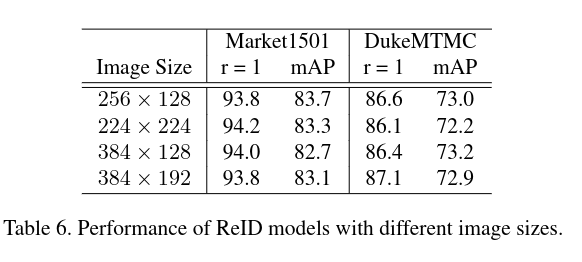
875 x 606
384 267
384 192
# 3.5 不同 Backbone 的影响
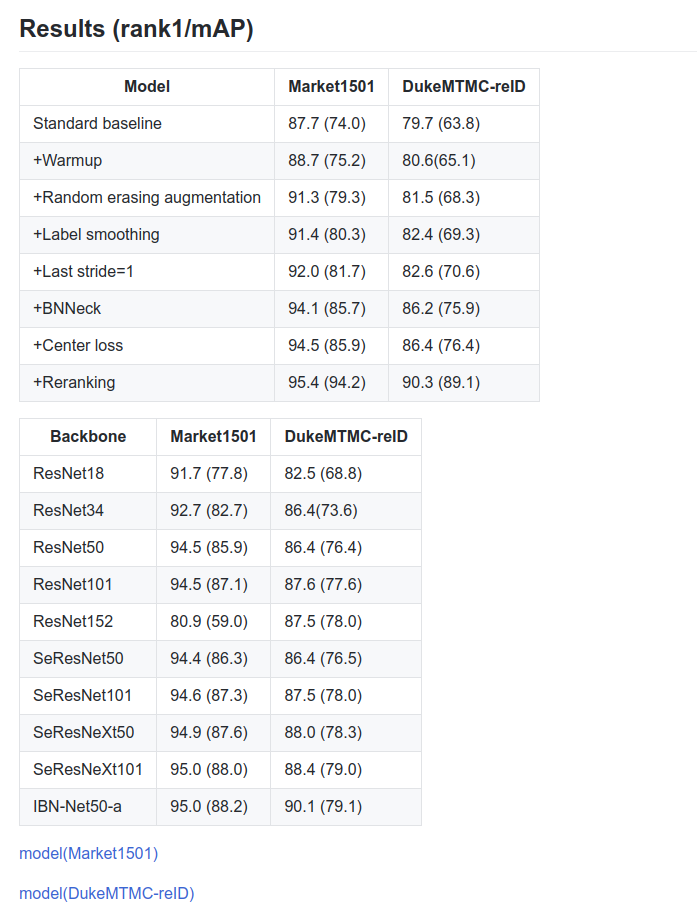
# 04、参考资料
# 4.1 本篇论文参考资料
paper:https://ieeexplore.ieee.org/document/8930088
code: https://github.com/michuanhaohao/reid-strong-baseline
slides: https://drive.google.com/file/d/1h9SgdJenvfoNp9PTUxPiz5_K5HFCho-V/view
# 4.2 其他代码链接
IBN-Network: https://github.com/XingangPan/IBN-Net
Pytorch ReID: https://github.com/layumi/Person_reID_baseline_pytorch
AICity-ReID-2020: https://github.com/layumi/AICIty-reID-2020/tree/master/pytorch
person-reid-triplet-loss-baseline: https://github.com/huanghoujing/person-reid-triplet-loss-baseline
fast-reid: https://github.com/JDAI-CV/fast-reid
reid-strong-baseline: https://github.com/michuanhaohao/reid-strong-baseline
pytorch-metric-learning: https://github.com/KevinMusgrave/pytorch-metric-learning
deep-efficient-person-reid: https://github.com/lannguyen0910/deep-efficient-person-reid
LUPerson: https://github.com/DengpanFu/LUPerson
person-reid-tiny-baseline: https://github.com/lulujianjie/person-reid-tiny-baseline
Huawei_DIGIX_ImageRetri_Top2: https://github.com/lin-honghui/Huawei_DIGIX_ImageRetri_Top2
PyRetri: https://github.com/PyRetri/PyRetri
deep-person-reid: https://github.com/KaiyangZhou/deep-person-reid
pytorch-center-loss: https://github.com/KaiyangZhou/pytorch-center-loss
CurricularFace: https://github.com/HuangYG123/CurricularFace
arcface.py: https://github.com/Tencent/TFace/blob/master/torchkit/head/distfc/arcface.py
curricularface.py: https://github.com/Tencent/TFace/blob/master/torchkit/head/distfc/curricularface.py
xbm 算法
# 05、华为 DIGIX 算法比赛方案学习
# 第二名:https://zhuanlan.zhihu.com/p/303371522
代码:https://github.com/lin-honghui/Huawei_DIGIX_ImageRetri_Top2
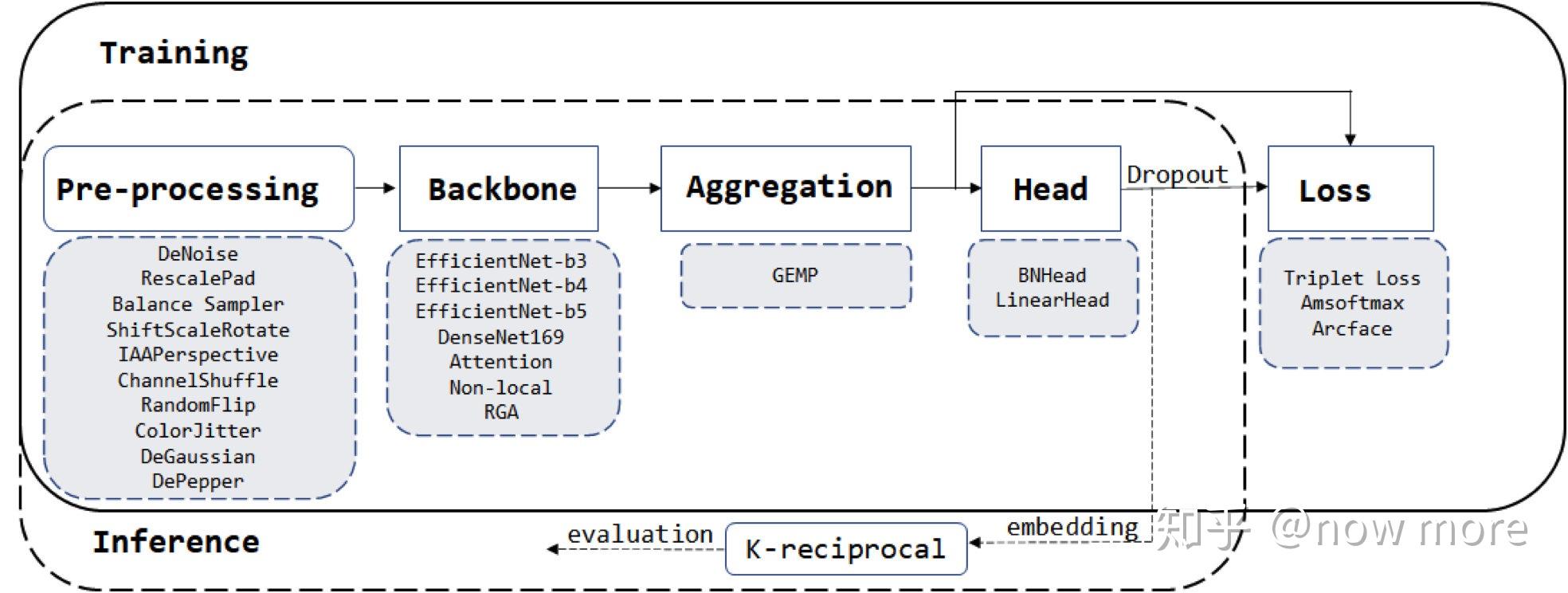
2.1 数据预处理
细粒度商品检索是一个较难的任务,数据预处理的目的是简化学习目标,修正样本分布、提高网络的泛化能力。
2.1.1 RescalePad
针对训练集中图像分辨率不统一问题,我们采取的策略是在保持物体形变情况下进行resize。具体操作是:padding 短边至长边相同大小,再resize到指定尺寸。
对于本次比赛任务,越大的 patch,越有利于图像细节信息的保留,更有助于性能提升,但显存和模型大小制约着patch增长。选拔赛时使用的显卡为1080Ti小水管,网络输入patch为448,512,决赛华为提供了较大显存的V100,使用了更大的分辨率576。
2.1.2 Balance Sampler
针对数据中存在的类别不平衡问题,我们过滤了类别数少于2的样本,网络训练时,以类别为基本单位进行采样,每次采样 n 个类别,每个类别采样 m 个样本,所有类别采样,保证每个类别以相同的概率被抽样。
实验中,不同的 n x m 采样的 batchsize 对实验结果有较大影响(2.2中讨论)。
2.1.3 DeNoise
本次比赛数据中,存在较多人为添加的高斯噪声和椒盐噪声,还有少量模式未知的噪声。噪声图像的存在会加大检索任务的难度,为降低噪声图像干扰,我们针对 gallery、query 中模式较为固定的高斯噪声、椒盐噪声图像进行离线修复。
2.1.4 数据增强
数据增强除了模拟商品颜色、旋转、形状、尺度等变化多样性外,针对2.1.3中噪声图像修复可能带来的边缘结构破坏问题(下图第2行,去噪后边缘信息被破坏),我们引入了DeGaussian和DePepper来提高网络的鲁棒性。本次比赛使用的数据增强有(示例图第1行从左到右):IAAPerspective、ShiftScaleRotate、ChannelShuffle、RandomFlip、ColorJitter、DeGaussian、DePepper。

2.2 模型和训练
2.2.1 模型设计
由于比赛模型大小的限制,Backbone选择时优先考虑了参数量较少的EfficientNet和DenseNet。我们也测试过ResNet、ResNext、RegNet等网络,但在这次的数据中表现并不佳;
Dropout 在这次的任务中提升显著,加上dropout和数据增强后,基本可以通过本地训练集acc预估线上分数。除dropout外也尝试过DropBlock、Disout等正则化方案,但因为和BNHead会发生冲突,而在之前的实验中去除BNHead是掉点的,后续没有进一步尝试。
决赛时我们最佳单模为EfficientNet-B4,初赛时最佳单模是DenseNet169-RAG。
2.2.2 模型训练
2.2.2.1 mini-batch
对于Triplet Loss 这类损失函数,增大 mini-batch,更有利于困难样本的挖掘,加速网络收敛。但显存制约着batchsize增加。我们使用XBM[4]来增大训练batch,但实验中观察到一个有趣现象:
- 开启XBM后,网络收敛确实加快,但并没有带来性能提升(甚至掉了一点点),在网络收敛的后期Triplet Loss依旧很高;
- 训练时,先开启XBM训练一段时间后,再关闭XBM(减小了batchsize)训练则网络性能有提升;
这里我们做了两个假设,一个是小batchsize训练的网络泛化性能更加,但在后续的对比实验证明并非如此。另一个假设是训练集可能存在重复的ID,盲目增大batchsize也增大了冲突概率,所以网络性能下降,并且也可以解释Triplet Loss很高的原因。
我们通过一个简单的实验进行验证:对于Arcface、Amsoftmax训练收敛的分类网络,全连接层的每一行都可以视为网络学到的一个类别中心,各个类别中心余弦距离表征着类别之间的相似度。设置阈值对余弦相似度较高的类别中心进行聚类可视化可以发现,训练数据集中确实存在大量的重复ID。比如 ID-1908、ID-1528、ID-363、ID-2979、ID-1475都为同款诺基亚手机,ID-770、ID-1205、ID-1082(见下图)都为同款华为手机,根据聚类结果粗略估计,大概有150~200重复商品ID,约占训练数据5~6%。
由于本次比赛不允许选手进行额外的标注,咨询了官方人员是否可以进行数据清洗也没有得到明确的答复,在确定数据集含有重复ID的情况下,我们也无法对数据集进行清洗。我们采取的方案是降低mini-batch中每次抽样的类别数n,而增大每个类别抽样数量m的方式,来降低发生冲突的概率。此外,由于重复ID的存在,Triplet Loss、Arcface等Loss margin取值也不应过大。
BackBone: EfficientNet、DenseNet
Pool:Generalized Mean Pooling [5]
Head : BNHead [1]
Loss : Triplet Loss + Arcface or Triplet Loss + Amsoftmax
正则化:dropout
其它组件:
- RAG [6]
- Nonlocal [7]
- IBN [8]
2.2.2.2 实验细节
超参数:根据选拔赛A榜进行调优。
- Triplet Loss:margin = 0.6,权重为1;
- Amsoftmax : margin = 0.35,scale = 30,权重为 0.25;
- Arcface : margin = 0.35,scale = 30,权重为 0.25;
- Dropout : p = 0.2;
训练加速:
- 使用 Pytorch 1.6 自动混合精度加速;
- 将 jpg 转 npy 加速IO;
- 模型参数冻结:DenseNet169只解冻最后2个Stage, Efficient-B3 冻结 15/25 block,B4冻结16/31 block, b5冻结20/38 block;
2.3 模型推理
2.3.1 尺度增强
推理时,增大 patch 为训练阶段1.1倍,以较小的计算代价换稳定的性能提升;
2.3.2 旋转特征对齐
商品角度旋转多样,而CNN对旋转不鲁棒,推理时将图像进行多个角度旋转预测,对得到的特征进行相加。
2.3.3 多主体场景优化
比赛后期上分到瓶颈期,通过统计发现存在部分样本,所有模型检索结果Top10几乎都不一致,这部分数据大概100+张,通过可视化总结,这部分样本大多为同个图像中存在多个主体、或者主体较小背景干扰严重。由于本次比赛不能引入额外的标注,我们无法引入额外的检测器进行主体检测再检索。我们尝试在仅使用attention map进行谱聚类的情况下进行主体检测,具体操作为:对于给定图像,计算attention map后进行阈值化处理,过滤出高响应的区域,对高响应区域像素进行 k=3 对最近邻建图,然后通过图切割得到多个子图,每个子图则大概率为一个主体,对切割得到的主体所在位置,对feature map 重新Crop & Pooling 再进行检索,最后对所有检测结果进行重排序。这部分优化虽然直接带来的结果提升不大,但对模型融合时提分显著。
2.4 后处理&模型融合
后处理:我们只做了 K-reciprocal,在 PyRetri基础上实现GPU加速(约加速3倍)和半精度优化(32g内存以内);
模型融合:我们使用加权投票的融合方式,统计检索结果中top10图像出现的频率及顺序(e.g. top1权重为1,top2权重为1/2 ... );
# 第三名:https://zhuanlan.zhihu.com/p/297669395
解决思路
长尾分布
- pk采样,每个batch里的类别数量是平衡的
- 二阶段训练,这个是参考一些解决长尾数据的论文思路,先用所有数据训练,让网络尽可能的学到更多的数据,然后这时网络会倾向于预测数量多的类别,第二阶段,对数量多的类别进行欠采样,经过二阶段训练,大约提升0.2%。
目标背景多
- 由于比赛赛题的限制,只可以用imagenet的预训练权重,而且只提供了id标签,我们采用了弱监督切割的方法,根据热力图的响应值,设定一个阈值,然后去掉背景区域,大约提升0.6%
测试集加入旋转,翻转等干扰操作
- 加入旋转操作,好多正常的图片,例如冰箱,成了横向放置,和正常情况不一样。我们也相应的训练阶段和测试阶段加入了翻转和旋转操作,验证集提升2%,由于提交次数有限,测试集没有经过验证。
类内差异大,类间差异小
- 用的经典的softmax+triplet训练,为了扩大难样本挖掘,我们还使用了xbm算法,辅助triplet训练。其实有尝试过其他sota loss,可能是参数不太合适,最后是softmax+triplet效果最好
trick
- gem
- rerank
- bnneck
- channle shuffle
- batchdrop
- 随机擦除
- 混合精度训练
模型
- resnest101
- resnest50
- res2net101
集成
- 我们用了六个模型,然后采用距离平均方法,我们也采用了投票法和concat形式,发现距离加权更好一些。
加权算法:
投票法
concat 形式
距离加权(√)
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12