 常见数据集的相关知识
常见数据集的相关知识
# 1、Cityscapes 数据集
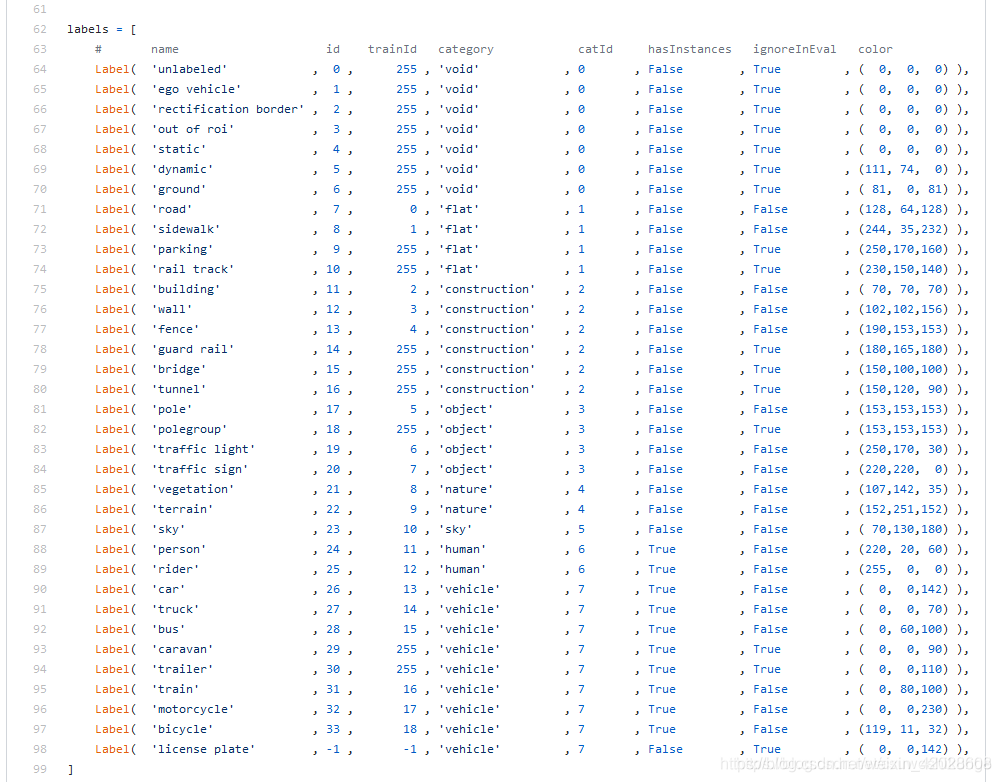
Cityscapes 是从五十个不同城市的街景视频序列中记录的数据集,拥有5000帧精细标注的图像,以及20000帧弱标注的图像。官方介绍中该数据集旨在用于:
- 评估计算机视觉算法在城市场景理解主要任务上的性能,包含语义级、实例级和全景语义级别
- 支持旨在利用大量弱标记数据的算法研究
- 在CVPR 2020 的论文中,Cityscapes 数据集也拓展了 3D 边界框的标记
- Cityscapes 数据集官网:https://www.cityscapes-dataset.com/
- Cityscapes 数据集下载地址:https://www.cityscapes-dataset.com/downloads/
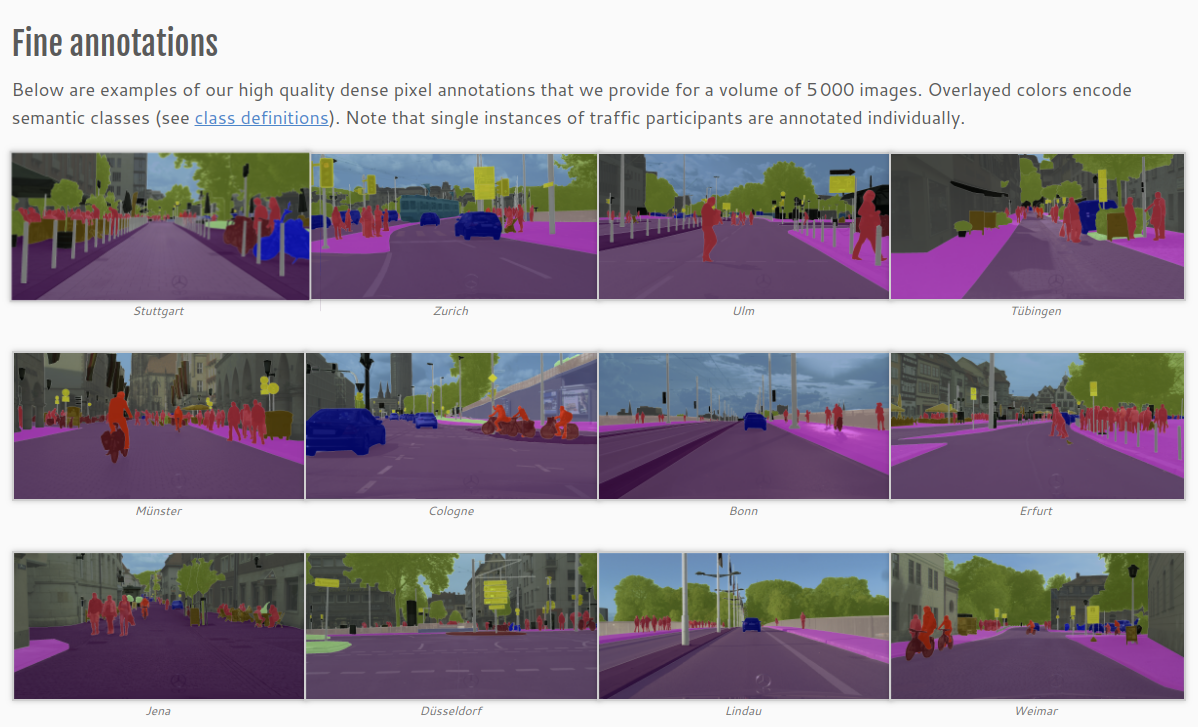
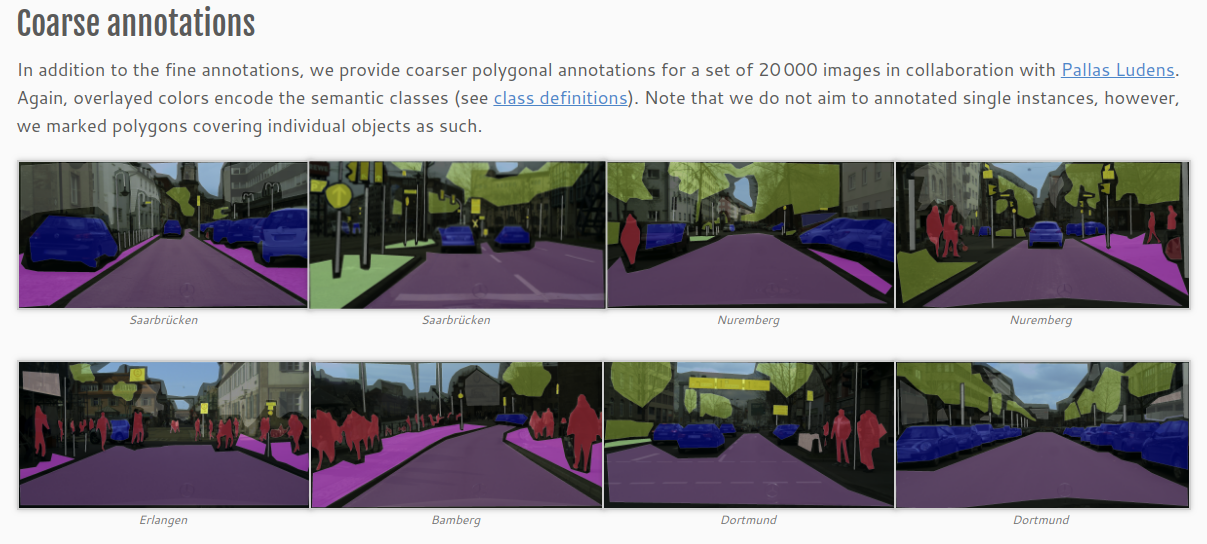
以下是 Fine annotations 和 Coarse annotations 的示例,在Fine annotations 中有 2975 张用于训练和,500 张用于验证,以及 1525 张用于测试。在Coarse annotations 中,有额外的 19998 张带噪标记的图像。此外还有带GPS、温度等元数据的数据集,此处不再介绍。
# 2、VOC 数据集
PASCAL VOC 挑战赛全称是 “Pattern Analysis, Statical Modeling and Computational Learning Visual Object Classes",PASCAL 是欧盟赞助的组织。这个竞赛从 2005 年办到了 2012 年,比较常用的数据集有 VOC 2007 以及VOC 2012
- PASCAL VOC 官网:http://host.robots.ox.ac.uk:8080/pascal/VOC/
- PASCAL VOC 2007:http://host.robots.ox.ac.uk:8080/pascal/VOC/voc2007/index.html
- PASCAL VOC 2012:http://host.robots.ox.ac.uk:8080/pascal/VOC/voc2012/index.html
下面简要介绍以下两个数据集的区别:
| 年份 | 数据统计 | 新内容 | 备注 |
|---|---|---|---|
| 2007 | 共有二十个类别: Person: person Animal: bird, cat, cow, dog, horse, sheep Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor 共有9963张图像,包含了 24640 个带注释的目标 | 类别从10增加到20;支持分割任务;在注释中加入截断标志;分类任务的评估方法改为Average Precision,以前是 ROC-AUC | 设立了20个类别,该数量将固定下来,并且这是为测试数据发布注释的最后一年 |
| 2012 | 共有二十个类别,训练集和验证集共包含11530张图像,包含27450个ROI 注释,以及6929个分割标签 | 分割数据集的规模显著增加;动作分类数据集中的人像带有身体关键点的标注 | 分类,检测以及person layout的数据集和 VOC2011 一样 |
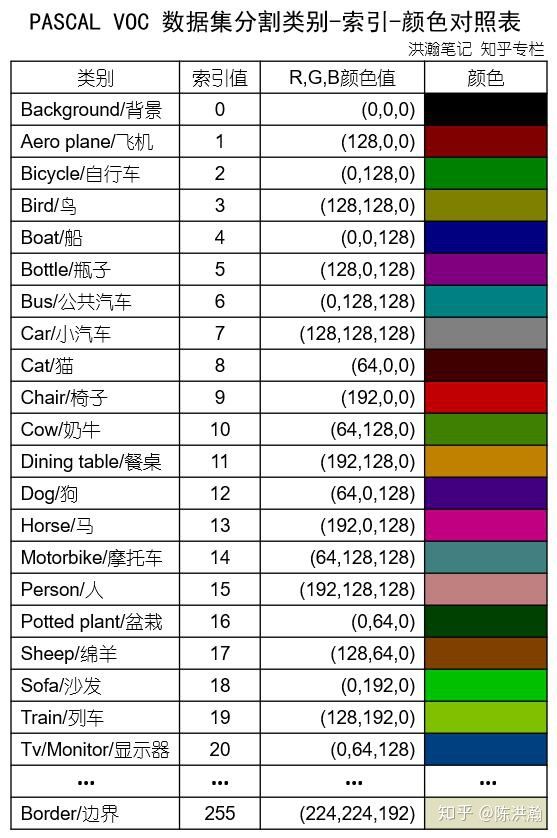
根据官网的分割 Examples (opens new window) 中所介绍的,类别索引是根据字典序来的:
(1=aeroplane, 2=bicycle, 3=bird, 4=boat, 5=bottle, 6=bus, 7=car , 8=cat, 9=chair, 10=cow, 11=diningtable, 12=dog, 13=horse, 14=motorbike, 15=person, 16=potted plant, 17=sheep, 18=sofa, 19=train, 20=tv/monitor)
在这篇 知乎文章 (opens new window) 中有PASCAL VOC 数据集类别到调色板的映射
4、PASCAL VOC 2012 Aug

额外的数据来自论文《Semantic Contours from Inverse Detectors》
- https://people.cs.umass.edu/~smaji/papers/contours-iccv11.pdf
- http://home.bharathh.info/pubs/codes/SBD/download.html
下面讲述以下如何将原始的PASCAL VOC 2012数据集和增强版的数据集合并到一起
VOCdevkit/VOC2012为原始PASCAL VOC 2012数据集
- images数据集的文件名为:JPEGImages,共17125张图片(其中2913张用于分割)
- labels数据集文件名为:SegmentationClass,共2913张图片
- 其中官方划分的train.txt 有1464张,val.txt有1449,测试集有1456张
benchmark_RELEASE为增强数据集
- images数据集的文件名为:img,共11355张图片
- labels数据集文件名为:inst,共11355张图片,为mat格式的(matlab格式)
- 其中官方划分的train.txt 有8498张,val.txt有2857张
voc数据集标签:voc_trainval:2913 ,voc_train:1464,voc_val:1449
sbd数据集标签:sbd_train:8498,sbd_val:2857
sbd_train(8498)`=`和voc_train重复的图片(1133)`+`和voc_val重复的图片(545)`+`sbd_train真正补充的图片(6820)
sbd_val(2857)`=`和voc_train重复的图片(1)`+`和voc_val重复的图片(558)`+`sbd_val真正补充的图片(2298)
所以可以得到的最大的扩充数据集应为:
voc_train(1464)+voc_val(1449)+sbd_train真正补充的图片(6820)+sbd_val真正补充的图片(2298)=12031张标注图
用原来的voc_val(1449)作为验证集,剩下的12031-voc_val(1449)=10582都可以用作训练,就是trainaug(10582)
合并之后的trainaug.txt 一共有10582张训练数据
- https://gist.githubusercontent.com/sun11/2dbda6b31acc7c6292d14a872d0c90b7/raw/5f5a5270089239ef2f6b65b1cc55208355b5acca/trainaug.txt
参考资料:
- https://blog.csdn.net/lscelory/article/details/98180917
- https://www.sun11.me/blog/2018/how-to-use-10582-trainaug-images-on-DeeplabV3-code/
# 4、ADE20k 数据集
# 5、COCO数据集
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12