 样本生而不等
样本生而不等
# 参考资料
https://www.techbeat.net/article-info?id=743
针对目标检测的正负样本采样问题,也就是挑哪些 bbox 送进 BBox Head 中进行训练
主要有两个方面
样本的不平衡性
- OHME 只考虑了样本的难易程度,可能会对噪声样本更加敏感
- Focal Loss 在单阶段检测器中非常work,而在两阶段检测器中的提升有限
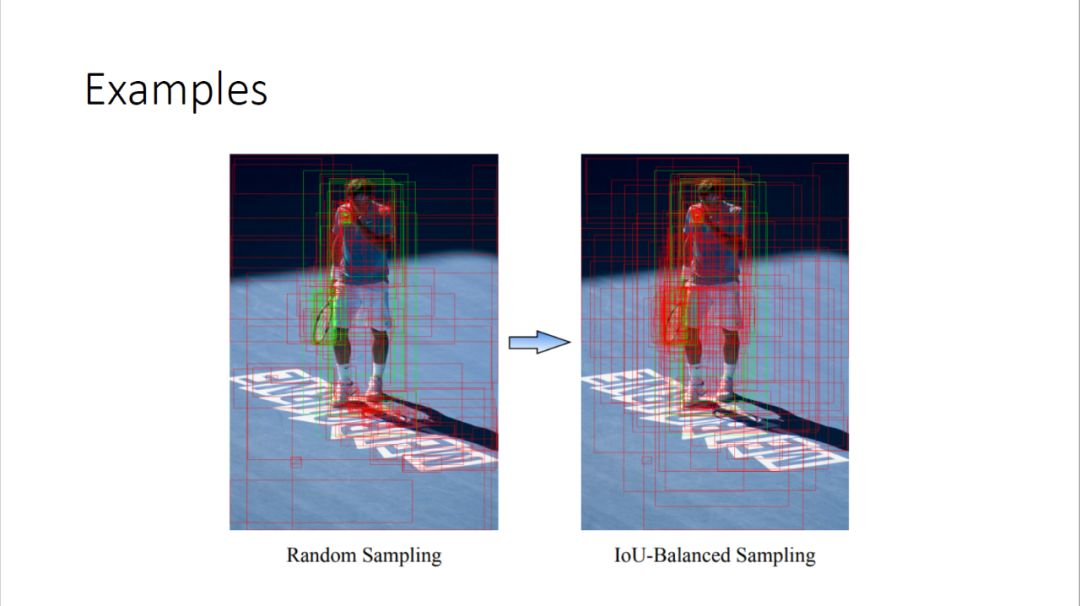
- 文章探寻了 IoU 和 困难度之间的关系,结论是:高 IoU 的负样本是比较困难的负样本。所以对于负样本采样,提出了 IoU-balanced Negative Sampling
- 第一步,把IoU的区间均匀的分成K个区间
- 第二步,在每个区间我们会sample N/K个bboxes
- 对于正样本采样,提出了 Instance-balanced Positive Sampling
- 如果整张图中有N个groundtruths的话,samples N个正样本,那么在K个ground truths附近,每个ground truth旁边sample N/K个正样本,同样,如果最后数量达不到要求,会用随机采样的框来补上。
样本的重要性
- 困难的样本是不是对于检测器来说是最重要的样本?
- 检测和分类分支对于样本的重要度评估是否一致?假定我有一个框,如果能够train出更好的分类器,是不是意味着检测性能更高?
- 通过观察得到的结论:
- 分类的准确率跟检测的准确率没有必然的关系
- 对于一个检测器,如果能够给每个物体周围给一个框一个非常高的score,这个框通常就是比较准的框,然后能够保证所有的物体都被cover到,那么这个检测器就应该是一个好的检测器,所以它跟分类的评价是不一样的,分类要求所有样本的平均性能尽可能高。
- 检测通常有两个分支,一个是分类的分支,一个是回归或者定位的分支,这两个分支是相互关联的。
- 关键结论
- 重新回顾 mAP 的计算过程发现:对所有的ground truth来说,IoU越高的框越重要。
- 重新回顾 FP 的计算过程发现:局部来看,分数最高的框是最重要的;全局来看,分数越高的负样本越重要。
- 提出了 Hierarchical Local Rank (HLR)
- 基于最终框的位置来衡量的,回归之后再衡量其重要性
- 正样本的 IoU HLR
- 第一步:会先计算Local Rank(这里都是以正样本为例),仍然有{A,B,C,D,E}5个正样本,对于A,B,C来说它们cover的是同一个人,所以它们是一组,然后D和E是一组,在每一组中,按它们的IoU进行排序,经过排序之后是C>A>B,D>E,这样我们就得到了一个局部的排序,针对每个ground truth附近的框的排序。
- 第二步:把每一组的TOP 1拿出来进行排序,比如ABC中的TOP 1是C,DE中的TOP 1是D,把C和D拿出来做一个排序,然后把TOP 2A和E也拿出来做一个排序,同样TOP 3也做一个排序,这样我们就得到了一个Hierarchical Local Rank,最终得到的排序是DCAEB。假设这张图中有K个ground truth,TOP K代表每一个ground truth周围IoU最大的框,接下来K个元素代表每个ground truth TOP 2 IoU的框。这就保证了分别跟之前对mAP进行分析时的两条结论相对应。第一条是对于每个样本IoU高的会排在前面,第二条是对于不同的ground truth IoU高的会排在前面。所以最终得到的HierarchicalLocal Rank刚好符合之前对正样本重要性的分析。
- 负样本的 Score HLR
- 对于负样本来说,选择的就是Score的Hierarchical Local Rank,这也是基于之前对负样本的分析,它的方式基本和正样本一样,把IoU换成Score。
- 提出了 PrIme Sample Attention(PISA) 方法
- Importance-based SampleReweighting(ISR)
- 把 Rank 映射成一个 loss weight
- 里面的loss还是用的Positive,对每个Sample都给它一个wi’或者wj’这么一个loss weight,wi’或者wj’是通过上面得到的wi做了一个归一化,因为如果随便加了一个loss weight,最后总的loss的数值变化可能会比较大,为了消除其它因素的影响,就会保证在加了loss weight之后,loss的数值跟不加它是一样的,所以就乘了一个归一化的项。
- Classification-Aware Regression Loss(CARL)
- 基于我们的思考分类和回归这两个branch不是完全独立的,而是耦合的。分类的分支会有一个cross entropy loss,回归的分支大部分会用一个smoothL1的loss,那么如何把这两支融合起来呢?
- 再加一个classifification-awareregression loss,就是carl,这个loss会把分类的Score经过一个函数的映射(这个函数跟刚才Sample reweight指数函数形式完全一样的),跟原始的regression loss相乘,这就是classifification-awareregression loss,为什么叫classifification-aware ,因为这个 regression loss是把分类的Score乘了上去,这里的si是指正样本label分类的Score。
总结
Sample Imbalance,IoU-balanced Negative Sampling和Instance-balanced Positive Sampling,在不带来overhead的情况下,有接近1个点的提升。
Sample importance,我们重新思考了什么样的sample才是重要的sample,也思考了分类任务和检测任务的区别,提出了Prime Sample的概念,来对检测器的训练进行优化。
上次更新: 2021/09/26, 00:09:41
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12