 Learning from Pixel-Level Label Noise A NewPerspective for Semi-Supervised SemanticSegmentation
Learning from Pixel-Level Label Noise A NewPerspective for Semi-Supervised SemanticSegmentation
# Learning from Pixel-Level Label Noise: A New Perspective for Semi-Supervised Semantic Segmentation
# 作者:北交团队
# 发表:Arxiv
# 摘要
这篇文章旨在解决半监督的语义分割问题,该问题定义为:拥有少许的像素级别的标签(强监督信号)以及大量图像级别的标签(弱监督信号)的语义分割。许多现有的方法致力于以图像级别的标签生成精确的像素级别的标注,然而我们观察到这些生成的标签包含许多噪声标签。基于这个 Motivation,作者提出以像素级的带噪学习视角来建模此问题。现存的标签带噪的方法,主要集中在图像分类的任务上,不能捕捉到一张图像中相邻像素标签之间的关系。所以,作者提出了基于图的标签噪声检测和纠正的框架来处理像素级别的带噪标签。对于使用 CAM 技术生成的像素级带噪标签,我们使用强监督信号训一个干净的分割模型来从这些带噪的标签中检测出干净的标签,使用的 loss 是交叉熵损失。
然后,作者使用了超像素图来表示像素间的空间相邻性以及语义相似性。最后我们使用检测出的干净标签来训一个图注意力网络,并用其来修正带噪标签。在PASCAL VOC 2012,PASCAL-Context 以及 MS-COCO 数据及上做了实验,并达到了sota的结果,并且超越了一些全监督的模型。
# 阅读
# 论文的目的及结论
论文想从带噪学习的角度来建模半监督语义分割问题,使用的方法是先对 CAM 生成的伪标签进行 clean 以及 noisy 的分类,再使用 clean 的标签训一个图注意力网络来修正 noisy 的标签,最终使用所有的图像再来全监督的去训最后的模型。
# 论文的实验
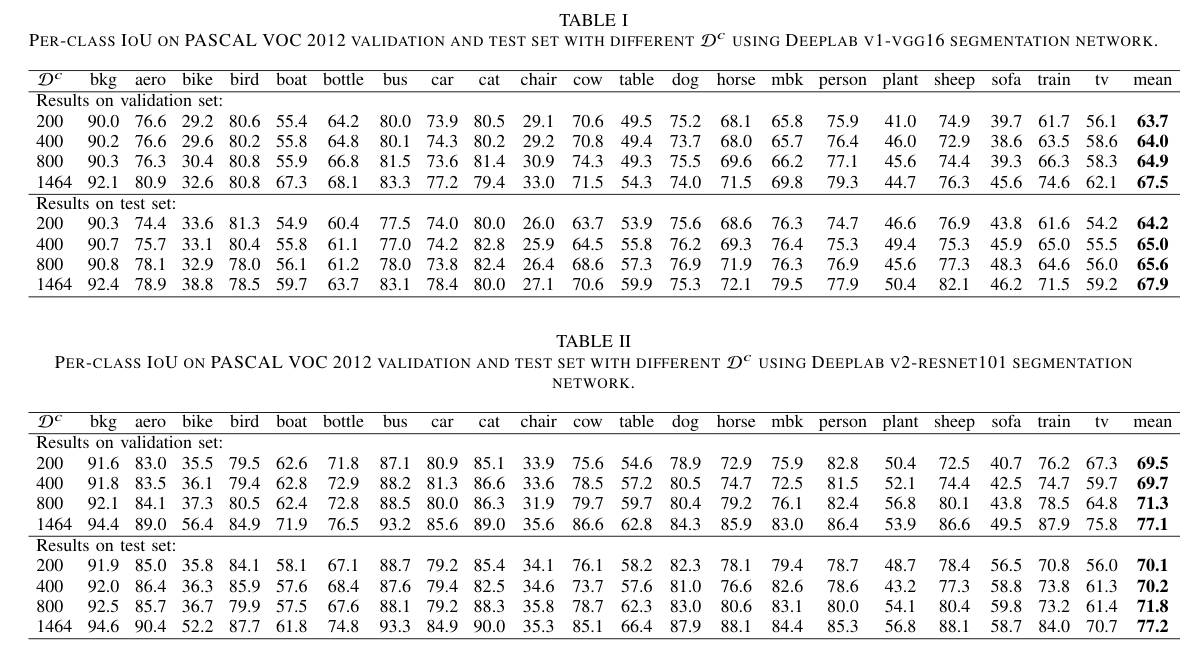
图一和图二展示了在 PASCAL VOC 2012 上的 mIoU 随着 增大的结果变化。
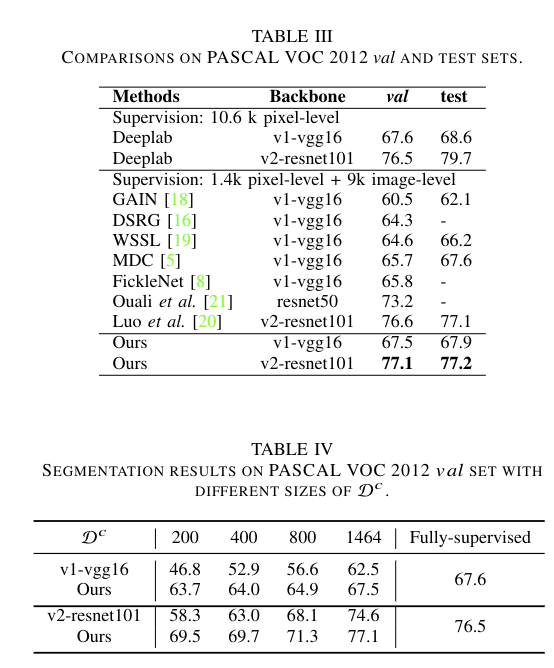
图三展示了和其他方法半监督语义分割方法的比较,图四展示了不同 下的分割模型结果,作者提出的方法甚至可以超过全监督的性能

图五是消融实验,展示了在有无噪声检测以及有无标签修正情况下的模型性能。图六也是消融实验,展示了 CRF 在伪标签和分割中的作用。
# 论文的方法
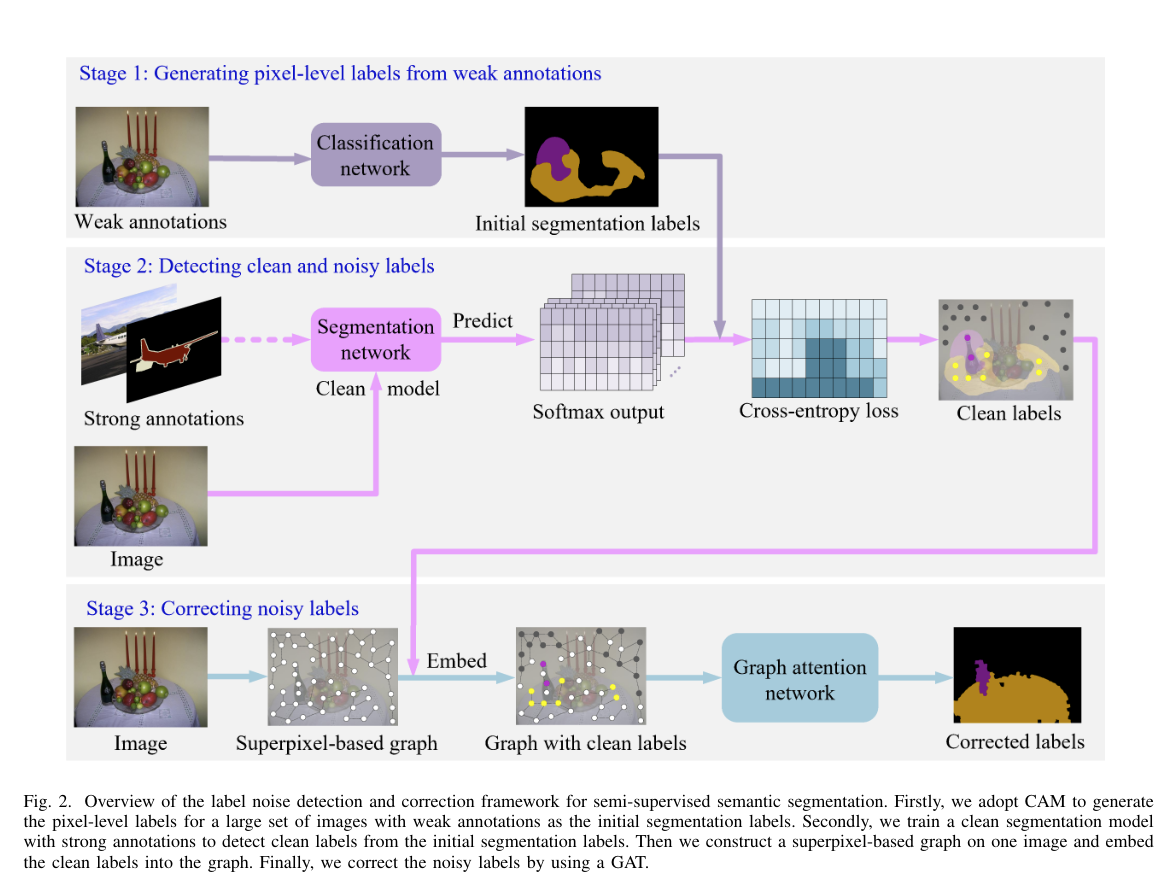
这是论文的方法总览,论文将其分为四个阶段。
- 首先,使用 CAM 生成 pixel-level 的标签
- 为了确保能够较为精确的检测出相对干净的伪标签,利用少量的强监督样本训练一个干净的分割模型
- 利用基于超像素的图建模图中像素的空间相邻性和语义相似性,利用 GAT 来修正带噪标签
- 修正后的标签作为伪标签来训一个分割网络
下面将分别介绍每个阶段的细节
# 1、从弱标注中生成 pixel-level 的标签
使用 CAM 来生成分割标签,架构就是典型的分类网络,在 GAP (Global Average Pooling)之后接全连接层。激活score 在0.05以下的视作背景,生成的伪标签作为初始标签
# 2、检测干净以及带噪的标签
先利用少量的强监督样本训练一个干净的分割模型,然后对每个弱监督样本都生成对应的预测。将该预测与 CAM生成的伪标签计算交叉熵损失来区分干净以及带噪的标签。并且设置一个阈值 来区分干净以及带噪的标签。利用这些干净的标签来训练后续的 GAT。
由于该阶段对 会比较敏感,作者对强监督样本都做了预测以及 CAM 生成伪标签的步骤,根据强监督样本的 loss 分布可以较为容易的确定适合的 参数,更多详细的实验在之后的消融实验里。
# 3、修正带噪标签
借鉴了【34】的方法,建立了一个基于超像素的图来建模像素的空间相邻性和语义相似度,然后 clean 的标签就被编码到图中,最后使用 GAT 来修正带噪标签。作者提到 GCN 也可以用于修正,也做了关于 GCN 和 GAT 的对比。
(1)超像素图的构建
超像素可以提供一个更大的,局部均匀一致的区域,并且能够保留很多用于精确分割的结构信息。作者将一张图像转化为一个超像素的图 ,其中 代表顶点集合, 代表边的集合, 代表邻接矩阵
顶点构建:使用 SLIC [41] 的方法将一张图转换为一个超像素集合,作者的实验中一张图分割为了1000个超像素,并且使用了深层的特征图来捕捉高层的语义特征,将其与超像素进行整合,整合的过程中用了线性插值恢复到原图尺寸。最终对于每个超像素都能够得到 512 维的 CNN 特征向量
边构建:利用图像中像素的空间相邻性和语义相似性来构造边。空间相邻性意味着相邻的像素更有可能有相似的标签,语义相似性意味着相同标签的像素可能共享了相似的语义信息。作者假设两个空间相邻的节点有相似的语义内容(同一类)。具体而言,先建立空间相邻矩阵 ,如果相邻即为1,不相邻即为0。语义相似度矩阵 ,每个超像素有 512 维的 CNN 特征向量,彼此之间的语义相似度即为 , 和 是每个超像素的特征向量, 是特征向量的维度,这里是 512。
邻接矩阵生成: 即为下面的公式,如果语义相似度小于 且小于顶点 所有邻接点语义相似度的最大值即为0,否则为1。此外,如果 为 0 的话,边 也会被移除
- 是均值
- 是标准差
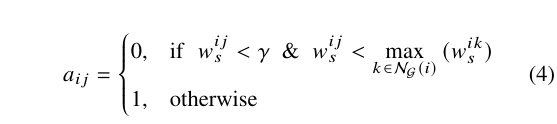
(2)修正带噪标签
编码干净伪标签:CAM生成的干净伪标签将被编码进图中作为监督信息来训练 GAT。为每个超像素分配类别的过程是多数原则
利用 GAT 修正噪声标签:参考[15],引入顶点上的自注意力机制以计算注意力系数,用于体现顶点 特征的重要性。为顶点 的邻接顶点都计算一个注意力系数 。为了系数能够跨顶点进行比较,利用 softmax 函数做了标准化。然后使用多头注意力来实现以上的图注意力机制,每个节点最后的输出特征如下:
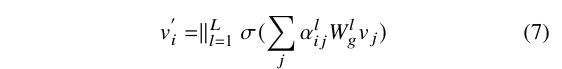
是由第 头注意力机制标准化之后的注意力系数, 是相应的输入线性变化的权重矩阵,在实验中,作者实现了两层的 GAT 用于标签的修正。修正的模型为 , 是由式 (7) 计算得到的超像素特征矩阵, 是由式 (4) 计算得到的邻接矩阵,所有干净伪标签的交叉熵损失被定义为:
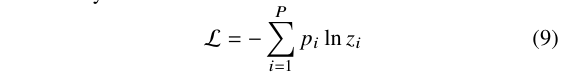
是超像素 所对应的标签, 是超像素的数量, 则是 GAT 对于该超像素的输出
# 5、训练分割网络
带噪的伪标签被 GAT 修正之后,可以根据其对应的超像素来恢复每个像素的标签,然后通过 CRF 对修正的分割标签做细化,以更好的估计物体的形状。最终所有的样本用于全监督学习的训练
# 论文的背景
将半监督学习视作伪标签噪声问题,核心点有两个:如何区分带噪标签以及如何对带噪标签做修正。前者作者直接用CAM 生成的伪标签以及用干净数据训练的分割模型的预测做一个交叉熵损失得到分数,再通过分数阈值进行区分;后者作者使用基于图的方法对超像素的一些约束进行建模,建模过程言之有理,不过如果对像素进行修正的我没有看懂。准备发邮件给作者问下
# 总结
# 论文的贡献
论文的主要贡献是从噪声的视角去看待半监督的语义分割任务,引入基于超像素的图建模图中像素的空间相邻性和语义相似性,利用 GAT 来修正带噪标签,也用到了CRF做细化,将修正后的标签一起再来训分割模型。
# 论文的不足
# 论文如何讲故事
# 参考资料
- https://arxiv.org/abs/2103.14242
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12