 Weakly-Supervised Image Semantic Segmentation Using Graph Convolutional Networks
Weakly-Supervised Image Semantic Segmentation Using Graph Convolutional Networks
# Weakly-Supervised Image Semantic Segmentation Using Graph Convolutional Networks
# 单位:國立陽明交通大學
# 作者: Shun-Yi Pan, Cheng-You Lu, Shih-Po Lee, Wen-Hsiao Peng
# 发表:ICME 2021
# 01 摘要
基于 image-level 类别标签来做图像的语义分割,常用的方式是使用 Random Walk 来传播 CAM 的分数,用全监督的方式来训语义分割网络。但是 Random Walk 的前馈机制没有添加任何的正则化,本论文提出了 GCN-based 框架。将完整伪标签的生成 formulate 为一个半监督的学习任务,为每张训练图像都去学习 2 层的 GCN,用Laplacioan 以及 Entropy 正则化的损失。
# 02 论文的目的及结论
该论文希望用 GCN-based 特征传播范式来替代 Random Walk.
Random Walk 主要依赖特征域上像素间的亲和度,来传播 CAM 的激活分数。论文提出的范式学习 GCN 来正则化特征传播,不仅有上述的特征亲和力信息,还利用了输入图像的颜色信息。
此外,本论文认为伪标签的生成是一个离线过程,所以训练了一个单独的GCN来优化每个训练图像的特征传播。 选择 GCN 而不是 CNN 的目的是因为它们在特征样本之间有不规则的亲和关系。
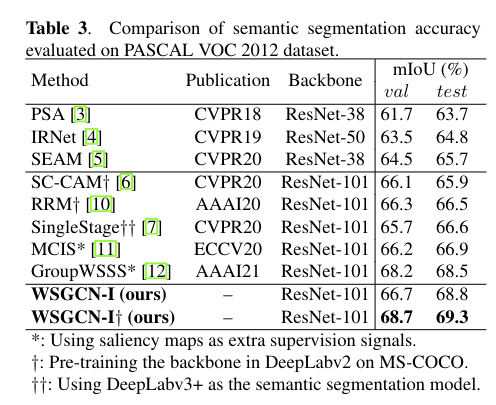
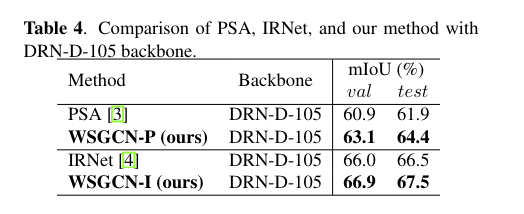
# 03 论文的实验
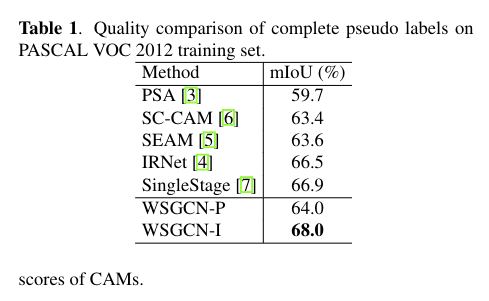
WSGCN-I 使用 IR-Net 生成的亲和度矩阵 以及 节点特征
WSGCN-P 使用 PSA 生成的亲和度矩阵 以及 节点特征
WSGCN-I使用边界检测网络[4]构建亲和矩阵,并将位于边界检测网络最后一层和1×1卷积层之前的特征作为节点特征。WSGCN-P 在指定亲和度矩阵 A 时遵循 AffinityNet [3],并使用语义特征作为节点特征 V 进行亲和度评估。

# 04 论文的方法
# 4.1 Framework Overview
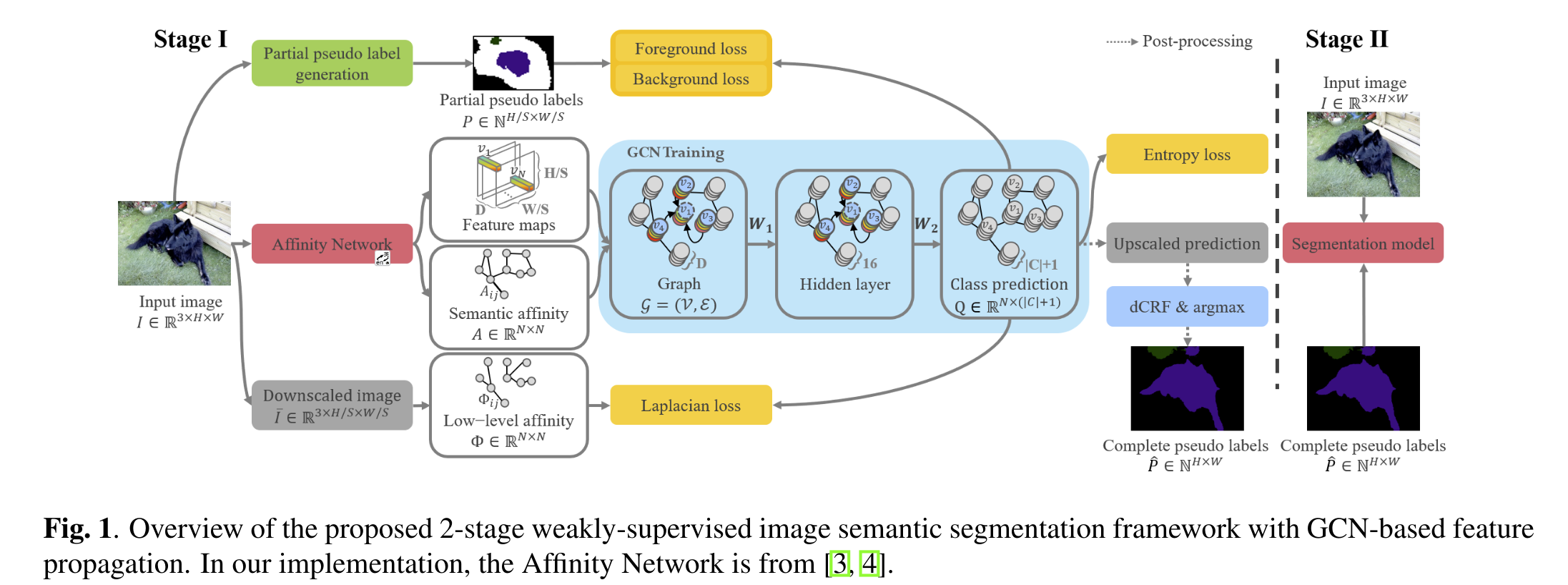
Affinity Network 来自 PSA 和 IR-Net,
Follow [3]和[10]来生成partial pseudo labels
在位置 (x,y) 上,伪标签 P(x,y) 会 assign 一个类别标签,C 是前景类别, 代表背景类别,还有 ignored 的标签
给定部分伪标签 P,我们认为生成完全伪标签 P 是 Graph 上的半监督学习问题。然后第一阶段的输出包括图像I的完整伪标签,在第二阶段用作训练语义分割网络的真实标签。下面详细介绍每个组件的操作。
# 4.2 Inference of Complete Pseudo Labels on a Graph
, 是一个 图,由点集 和 边集 组成,一个边会包含两个点以及边的权重。
- 节点总数
- 代表下采样的因子
- 节点特征的选择在 4.1 小节有详细说明
- 的伪标签表示为
- 边的权重 度量节点 和 的亲和度
- 由于 GCN 可以选择广泛的亲和力措施,所以在实验中测试了两种不同的措施 [3,4]
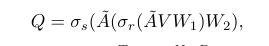
为了生产完整的Pseudo Label,论文提出了利用图 以及 2 层的 GCN 进行特征传播以及推理,推理的方式如上
点集 是节点特征的 D 维向量组成的矩阵 ,
是 , 是 ,是两个可学习的网络参数
和 分别是 ReLU 和 softmax 的激活函数
,其中 表示identity matrix, 是亲和度矩阵
背景类也要算上,所以是 ,
,每一行表示像素 在特征域上语义类别的概率分布,这些概率分布会进行插值(使用双线性插值)后恢复到全分辨率,然后以通道方式应用 dCRF [13] 并在每个像素处取最大跨通道以获得完整的伪标签。
# 4.3 Training a GCN for Feature Propagation
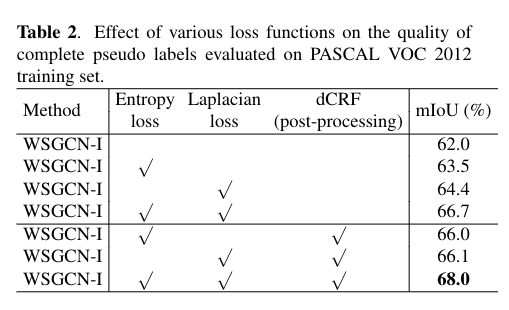
论文将标签的细化建模为 Graph 的半监督问题,设计了四个损失。
- foreground loss
- background loss
- entropy loss
- Laplacian loss
总损失
和 就是超参数,前面两个就是在特征域上前景和背景像素的交叉熵。前景部分有partial pseudo labels ,背景像素为 。将交叉熵分成前景组和背景组背后的基本原理是解决这两类像素之间的不平衡问题。
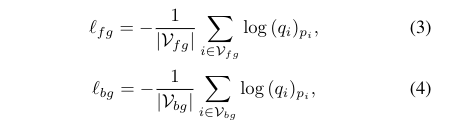
对于特征域中那些伪标签 被标记为 ignored 的像素,例如未标记的像素,我们施加以下熵损失,要求对其类别预测的不确定性应最小化。 换句话说,它鼓励那些未标记的像素的类别预测 近似于 one-hot vectors。
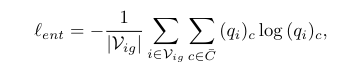
其中̄ , 指的是未标记的像素。 此外,由于观察到具有相似颜色值的相邻像素通常具有相同的语义类别,我们引入了 Laplacian loss 以确保类别预测与图像内容的一致性。 这种先验知识以拉普拉斯损失的形式被纳入GCN的训练中。
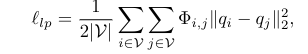
该 loss 旨在根据反映像素和像素的颜色值和位置的相似性的权重 ,最小化像素 和周围 像素的类别预测之间的差异(在 正则化来度量)
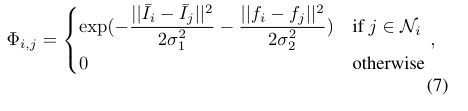
定义在上图,
表示点的坐标
指的是像素 处的颜色值
σ1=√3, σ2= 10 是超参数
定义为 的窗口
Φ 依赖于 low-level 的颜色和空间信息来正则化 GCN 输出,要与亲和度矩阵 区分开来。亲和度矩阵 使用高级语义信息 [3, 4] 来指定用于特征传播的 GCN 的图结构,接下来将详细介绍
# 论文的背景
# 总结
# 论文的贡献
# 论文的不足
# 论文如何讲故事
# 参考资料
https://arxiv.org/abs/2103.16762
https://github.com/Xavier-Pan/WSGCN
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12