 (DeepLabv1) Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
(DeepLabv1) Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
# (DeepLabv1) Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
# 单位:KAIST
# 作者:Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille
# 发表:ICLR 2015
# 摘要
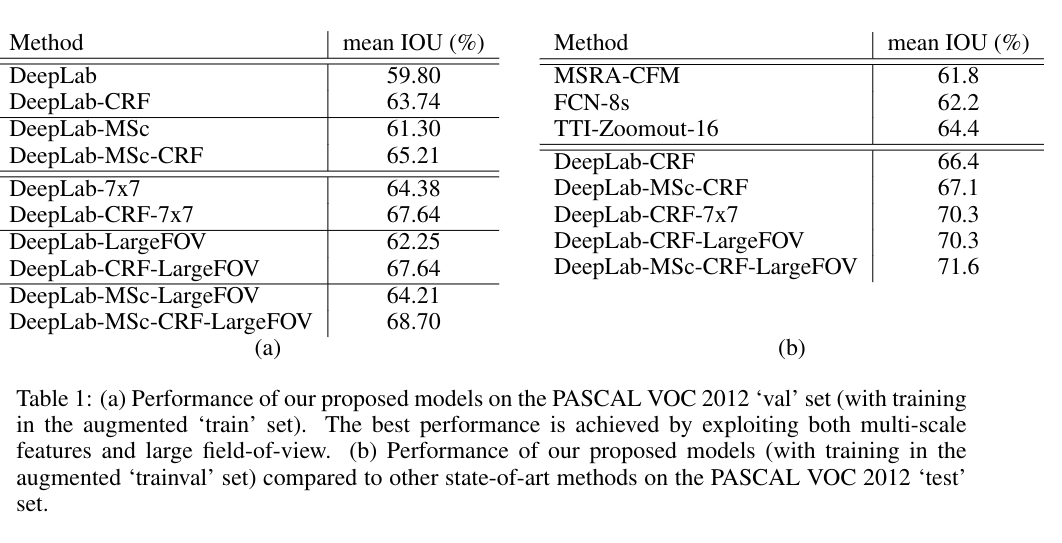
该工作将深度卷积神经网络和概率图模型结合来解决像素级分类问题(又称语义分割)。发现 DCNN 最后一层的响应不足以定位精确的物体边缘,这是因为不变性的性质使得 DCNN 对 high-level 的任务很有效。作者将 DCNN和 CRF 结合起来,以克服深度网络的这种不良定位特性。量化结果表明,DeepLab 系统可以定位很精确的目标边缘,在 PASCAL VOC-2012 数据集上达到了新的 SOTA 结果,测试集上的性能为 71.6% 的 mIoU。作者分析了性能提升的主要两点原因:预训练网络(VGG-16)的利用以及空洞卷积的应用
# 阅读
# 论文的目的及结论
# 论文的实验
# 论文的方法
# 3 用于密集图像标记的卷积神经网络
# 3.1 使用空洞卷积进行高效的密集滑动窗口的特征提取
空洞卷积是从小波变换的论文中得来的,使用空洞卷积算法可以使8倍的下采样达到32倍下采样的效果?
VGG-16 网络在 ImageNet 数据集上预训练,将1000路的分类器变为了21类,
# 3.2 使用卷积网络以控制感受野尺寸以及加速密集计算
在 VGG-16 网络中,图像的输入尺寸为 ,其全连接层有 4096 个 的卷积层,是计算瓶颈。作者降低了输入尺寸,并且减少了全连接层的个数,以加速密集计算
# 4 详细的边缘恢复:全连接条件随机场以及多尺度预测
# 4.1 深度卷积网络以及其定位挑战
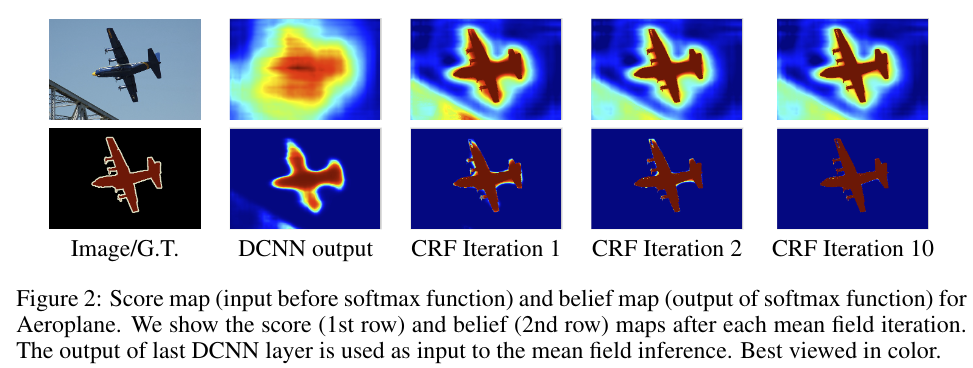
如上图所示,DCNN 的 score map 可以可靠地预测图像中对象的大致位置,但不太适合精确指出它们的确切轮廓。最大池化层被证明对图像分类任务来讲十分有效,但其会增加不变性以及大感受野,使分割问题更具挑战
# 4.2 用于精确定位的全连接条件随机场(后续需要专门分析一波代码)
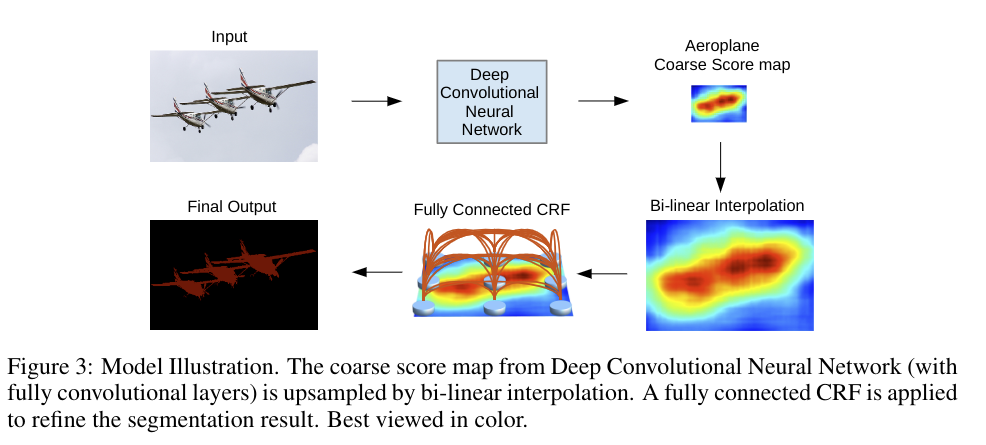
在传统方法中,条件随机场被用作平滑的带噪分割图的预测图。通常这些模型包含一个能量函数使得相邻的节点耦合,有利于空间上相似像素的预测标签分配,可以减少错误预测
使用了全连接条件随机场,能量函数是:
E(x)=\sum_\limits{i}\theta_i(x_i)+\sum_\limits{ij}\theta_{ij}(x_i,x_j)
是像素级别的标签,使用单元势能 , 是像素 的标签分配概率。成对势能是
如果 则 ,否则则为 0
每个 都是的高斯核,其由 像素提取的特征决定,并且由参数 来加权,第一个核取决于像素位置和像素颜色强度,而第二个核只取决于像素位置,几个参数控制着高斯核的尺度
# 4.3 多尺度预测
使用多尺度预测的方法来提升边缘定位的精度,我们在输入图像和前四个最大池化层每个输出上附加两层MLP,其特征图与主网络的最后一层特征图相连接
# 论文的背景
# 总结
# 论文的贡献
# 论文的不足
# 论文如何讲故事
# 参考资料
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12