 (HPT) Self-Supervised Pretraining Improves Self-Supervised Pretraining
(HPT) Self-Supervised Pretraining Improves Self-Supervised Pretraining
# Self-Supervised Pretraining Improves Self-Supervised Pretraining (opens new window)
# 作者:UC Berkeley
# 代码:Repository providing a wide range of self-supervised pretrained models for computer vision tasks. (opens new window)
# 摘要
自监督的预训练在很多视觉任务上被证明是有效的,但其要求也较高,较大的计算开销,较长的学习时间以及大规模的数据,并且其对数据增广的方法是十分敏感的。先前的工作表明:与其目标域数据大相径庭的源域上进行模型的预训练(例如用于医学影像领域的模型在 ImageNet 上预训练),会比随机初始化重头训的模型性能还要差。
本篇论文探索了 HPT (分层预训练范式),通过已有的预训练模型来初始化预训练进程可以减少拟合时间,并提升精度。通过在 16 个视觉数据集上的实验,HPT 的拟合速度可以比以往方法快 80倍,提升了模型的精度,并且还提升了自监督过程中对于数据增广方法的以及预训练数据量的鲁棒性。总而言之,HPT 提供了一个简单的框架利用更低的计算资源获得更好的预训练表示。
# 论文的目的及结论
降低计算开销
提升拟合速度以及模型精度
提升自监督方法的鲁棒性
# 论文的实验
# 4.1 实验数据集介绍
文章在很多数据及上做了评估,包括航空领域的的 xView 和 RESISC 的数据集,自动驾驶的 BDD 以及 VIPER 数据集,医学影像的 Chexpert 和 Chest-X-ray-kids 数据集,自然界的 COCO-2014 以及 Pascal VOC 2007+2012,以及 DomainNet 和 Oxford Flowers。
# 4.2 实验设置介绍
自监督的预训练通常都使用如下的三种评估方法:
- 可分离性:测试线性模型能否根据学到的特征区分数据集上的不同类别,好的特征表示应当是线性可分的
- 迁移性:测试模型在新的数据集和任务上 finetune 后的性能,好的特征表示会更容易泛化到下游的任务中。
- 半监督:测试模型在有限数据标注下的性能,越好的特征表示会有越少的性能下降。
在实验中,作者使用 MoCov2 作为自监督算法,MoCov2 使用了 InfoNCE 损失函数,是很多基于对比学习的预训练算法的核心。所有的训练都是使用 4 个 GPU 在标准的ResNet-50 backbone 下进行,使用 MoCo 的默认训练参数(超参数都放在附录中)。文章定义了四个自监督预训练的策略:
- Base:将训了 800 个 epoch 的 MoCov2 模型迁移,并且使用目标数据集更新 BN 的非训练的mean (均值)和varience(方差),作者提出调整BN的均值和方差可以提高迁移学习的性能
- Target:在目标数据集上随机初始化参数,使用 MoCov2 进行训练
- HPT:使用 MoCov2 论文中的在ImageNet上训了 800 epoch 的模型作为初始模型,在对目标数据集进行预训练之前,选择性地对源数据集进行预训练。
- HPT-BN:只训练 BN 的均值和方差两个参数
现有的工作在进行性能评估时都十分依赖预训练的超参数,但是在实践中无法使用未标记数据的评估效果来调整超参数,因此,为了强调 HPT 的实践效果,我们使用了默认的训练超参数,batch size 设置为256。
# 4.3 定量的实验结论与分析
4.3.1 线性可分的分析
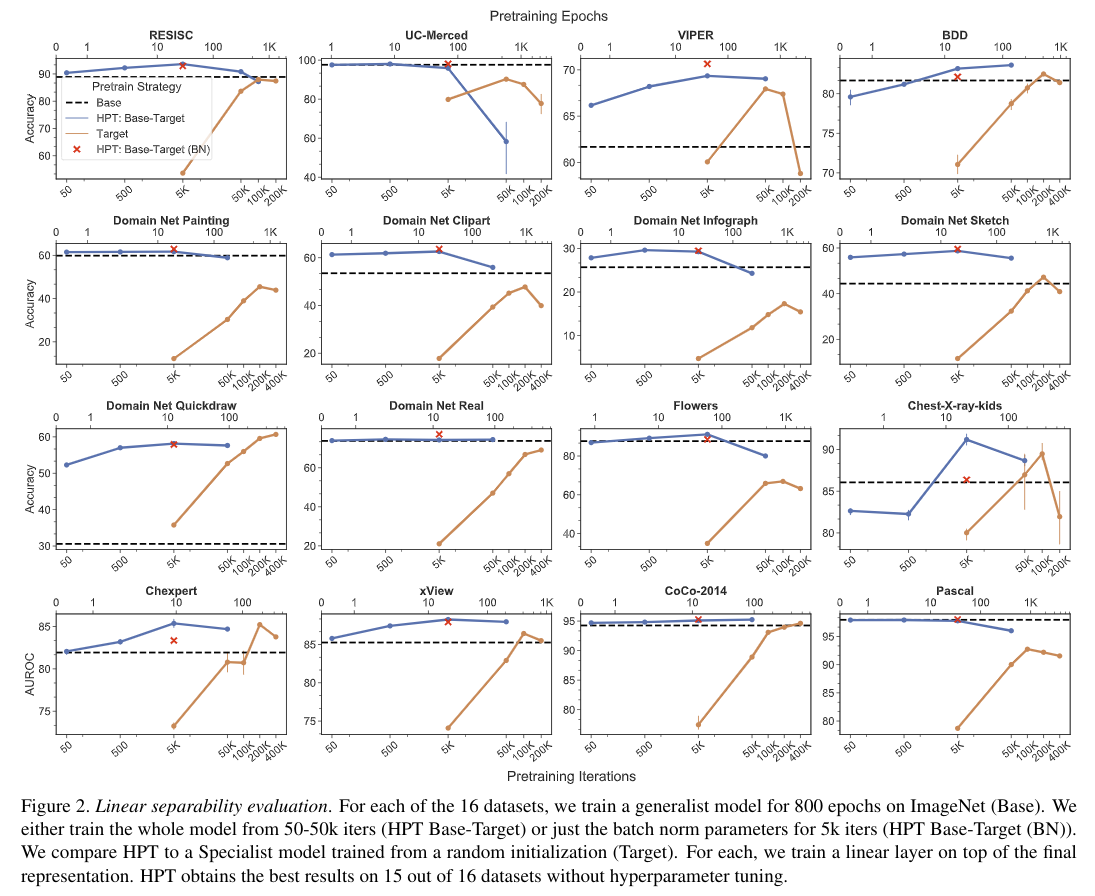
首先通过一个线性可分的评估器评估了所提取特征的质量。将 batchsize 设置为 512 训练一个线性模型,最高学习率为{0.3, 3, 30}(???迷惑)。与文献[29] 类似的是,我们也使用steps而不是epochs来允许夸数据集的计算代价比较。对于Target 预训练而言,作者训练了{5k, 50k, 100k, 200k, 400k} steps,如果在100k 到200k steps 中性能提升的话我们才训练400k steps。为了做参考,单张P100的 GPU-Day 为25k steps。我们预训练 HPT 对于很多{50,500,5k,500k} steps,HPT-BN 预训练 5k steps后我们可以观察到性能上的微小变化。
上图是他们论文的 Linear separability evaluation 实验结果。第一步都是在 ImageNet (Base)上训800 个 epoch,第二步有两种实验设置,
- 以 HPT Base-Target 的方法训 50、500、5k、50k 个 iteration
- 以 HPT Base-Target(BN) 的方法训5k、50k、100k、200k 、400个 iteration
在16个数据集中的15个都观察到了 HPT 在 5k steps后就基本收敛了,并且这一现象与目标数据集的大小无关。 HPT 以及 HPT-BN 比Base transfer 以及 Target Pretain 组表现的更好,即使他们训了400k steps,这一速度快了80 倍。唯一一个Target pretraining 优于 HPT 的数据集是 quickdraw (一个众包收集的庞大的绘画二分类数据集)这表明如果存在较大的域间差异,直接的 transfer 的话是不太 work 的。
HPT 在很多数据集上都提升了性能,在和 ImageNet 十分相似的数据集上和Base transfer 相近的表现,在两个医学数据集上 HPT 和 Base Transfer 也有相近的性能,但 HPT 只需要训 5k steps,而Base Transfer 需要训200k 和 100k 个 step。
此外,HPT 在 5k steps 之后出现过拟合现象,尤其是在较小的数据集上,因此作者建议采用非常短的 HPT 预训练步骤,例如 5k iterations,并且这与数据集大小无关。
4.3.2 半监督的迁移能力分析
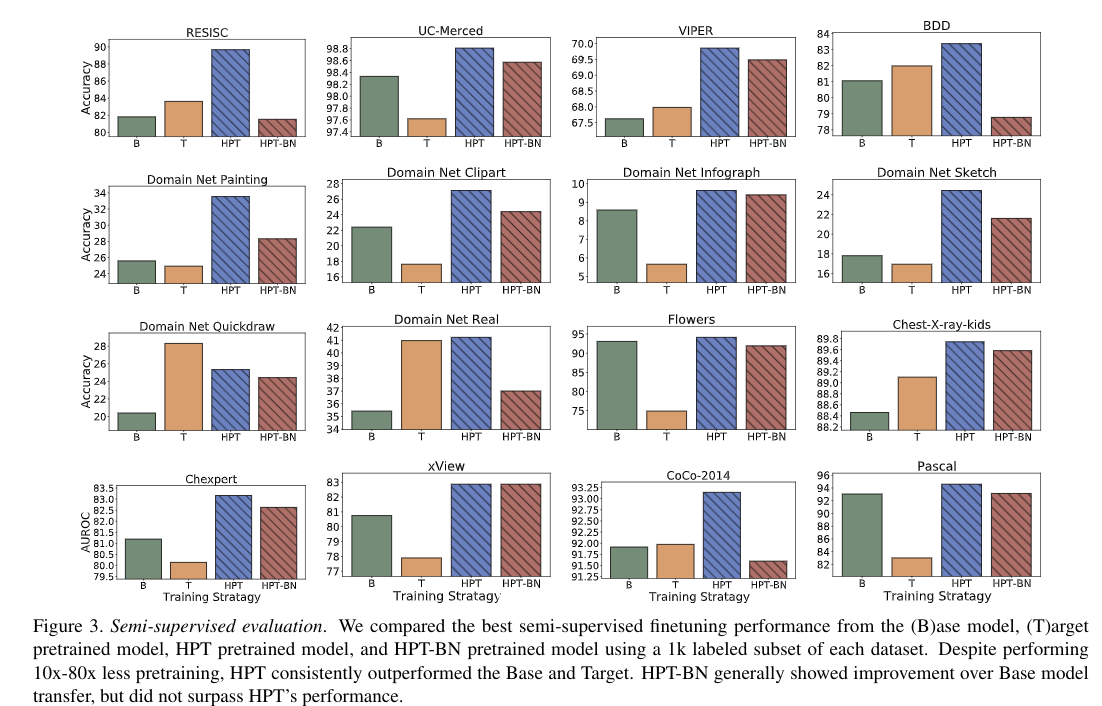
该实验测试的是额外预训练的收益是否会在 finetuning 模型参数的过程中被抵消。对于每个预训练策略,我们选择了在线性可分的实验中表现最优的模 型,使用了1000个随机挑选的标签(没有考虑类别均衡),但每个类别都会至少出现一次。作者使用了两种学习率的组合(0.01,0.001),以及两种finetuning 的 schedules (2500 steps,90 epochs),batch size 设置为 512,记录了每个数据集和模型最优的性能
上图是他们论文的 Semi-supervised evaluation 实验结果,验证了方法的半监督 finetuning 的性能。带条纹的 bar 就是 HPT pretraining 的结果,作者观察到和线性可分性验证类似的结果,HPT 在 其中 15 个数据集上都有最好的性能,除了 quickdraw 数据集(domain gap 过大)。一个关键的结论是 HPT 在半监督的实验设置下也是有性能增益的,HPT 和 Base model 的特征表示有足够的区分度,以至于完整模型的 finetuning 也无法说明变化。
作者还注意到 HPT-BN 在 线性可分性实验中有时会比 HPT 好,但是在finetuning 所有参数的时候HPT-BN 从未超过HPT 的性能。这个结果表明:预训练只调整 BN 参数获得的性能增益,在有监督的 finetuning 下是冗余的。还有一个发现是:Base 和 Target pretraining 的性能表现 对数据集是高度依赖的,但HPT 是一直都有较好的性能。
# 4.3 预训练的质量分析
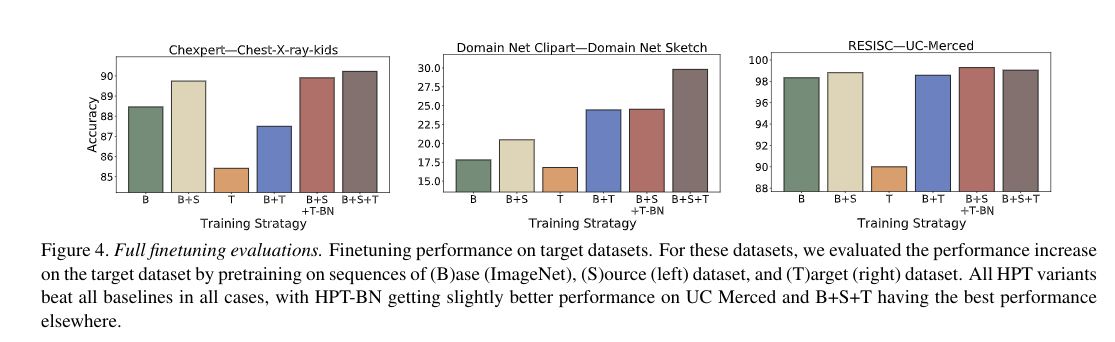
这个实验探索的是,首先在源域上进行 pretraining,再在目标域上进行 pretraining,最后再transferring 任务上的 HPT 的性能。测试了三个目标域的数据集:Chest-X-ray-kids,sketch,UC-Merced。我们为每一个目标域都选择了源域,选择超过 Base model 最优的性能。生成了三种实验
- ImageNet -> Chexpert -> Chest-X-ray-kids
- ImageNet -> clipart -> sketch
- ImageNet -> RESISC -> UC-Merced
上图比较了对目标域的1000个数据的子集进行finetuning,测试了如下策略
- B:直接使用Base model
- T:直接使用Target model
- B+S:Base 后使用 Source pretraining
- B+T:Base 后使用 Target pretraining
- B+S+T:Base 后使用 Source pretraining 再使用 Target pretraining
- B+S+T-BN:Base 后使用 Source pretraining 再使用 Target pretraining BN 的参数
结论表明,HPT 策略取得了最优性能。
# 4.4 对下游任务(检测和分割)的迁移分析
**使用的模型:**对于Pascal 和 BDD数据集,对 Faster R-CNN R50-C4 模型使用HPT 预训练策略,再在目标数据集上进行 finetune。对于COCO数据集,使用Mask-RCNN-C4。每个实验跑三次,记录 COCO AP 的中位数结果。
**使用的train/valid/test划分:**对于Pascal,在train2007+2012数据集上做finetuning,在test2007上做测试。对于BDD数据集,使用官方的train/test 的划分,从训练集中挑10k的图像作为验证集。对于COCO数据集,使用2017版的划分,在1x的schedule下进行训练
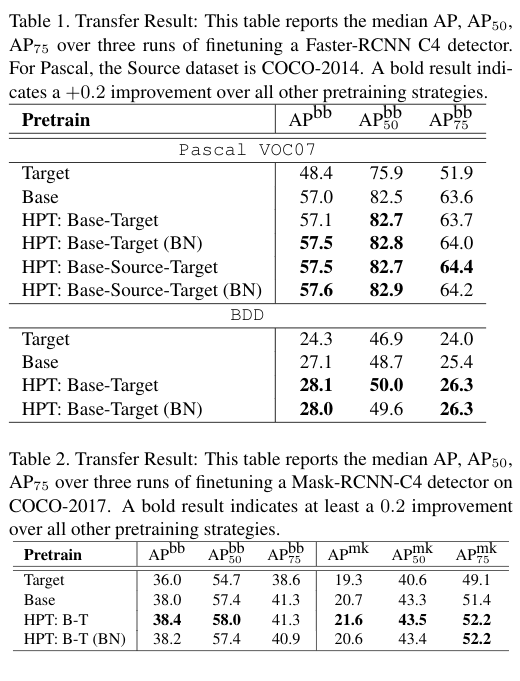
上面的表格比较了各个策略在三个数据集上的性能。HPT策略(BT 以及 BT-BN)的性能都要优于常用的Target 和 Base 方法。Pascal数据集上的 B-S-T 策略在pretraining 所有模型参数的时候有性能提升,并且如果仅仅对BN的参数进行pretraining的时候,结果仍然保持一致。这表明,虽然 BN 的参数可以找到更好的pretraining模型,但是普通的 从 source-target 的pretraining 却不总是能够带来性能的增益。
跨数据集来看,整体的性能收益较小,但是我们认为这些结果表明,无论是 MoCo 在ImageNet 上的pretraining 还是 在目标数据集上的finetuning任务,HPT 没有直接学习冗余信息。还有一个发现是:在目标检测任务上,仅仅tuning BN 的参数也可以带来性能的增益。
# 4.5 HPT 的鲁棒性
这一部分研究了 HPT 对影响自监督预训练(例如增强策略和预训练数据集大小)有效性的常见因素的鲁棒性。对于这些鲁棒性实验,我们使用了BDD,RESISC和Chexpert数据集,因为它们提供了数据域和大小的多样性。我们使用与第4.2节相同的超参数来测量线性可分性。
数据增强策略的鲁棒性
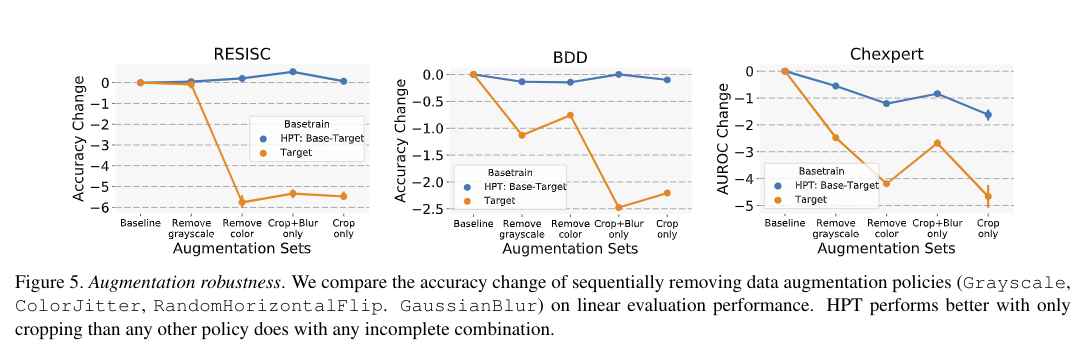
预训练数据集规模的鲁棒性
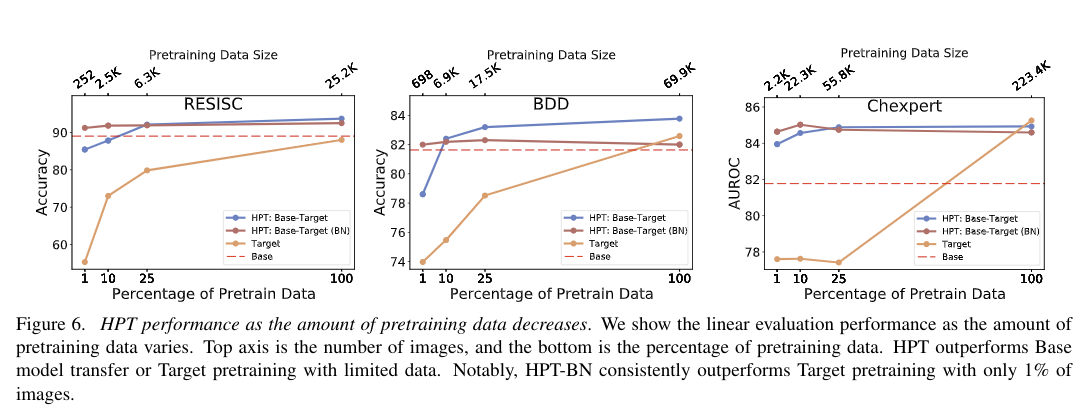
# 4.6 Domain Adaptation 的相关分析
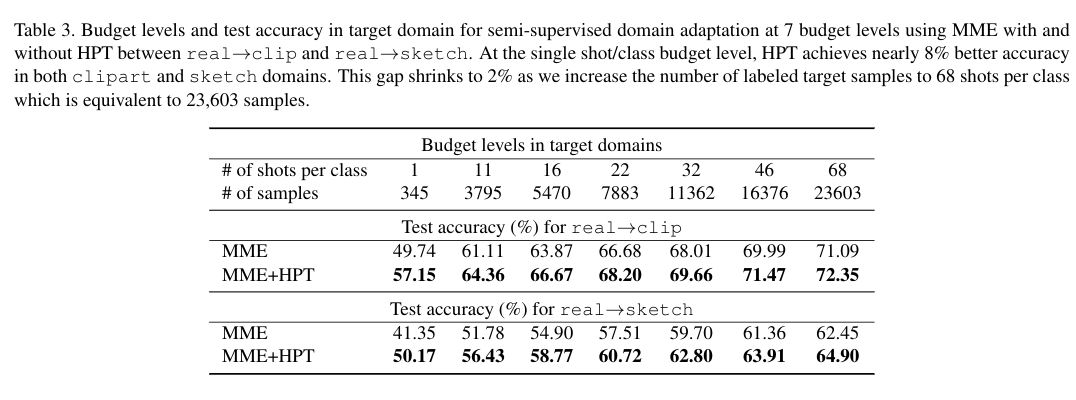
作者将HPT 应用于Domain Adaptation。目标是给定源域上有标注的数据进行训练,然后在未见过的目标域上进行图像分类任务。训练的步骤如下:
在标准的 MSRA ImageNet 模型的基础上,使用 HPT 策略在源域和目标域数据集上再去训一个模型。用这个模型去初始化MME(一种半监督方法) 的特征提取器。在每个budget level 的末期,对目标域的整个测试集做性能的评估。我们在拥有 7个 budget level,345个类别的DomainNet 数据及上开展了实验,随着目标标签的增加
- from real to clip
- from real to sketch
使用 EfficientNet_B2 作为backbone
# 论文的方法
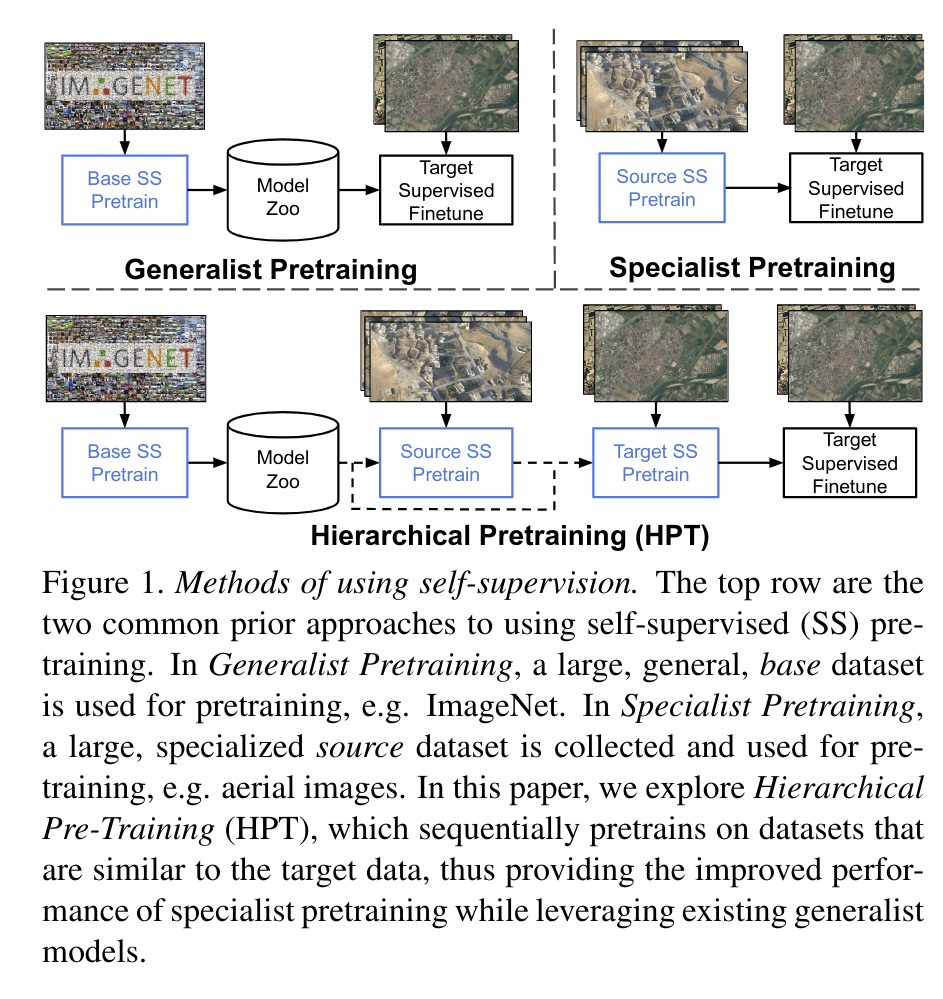
# 论文的背景
# 总结
# 论文的贡献
HPT 的 novelty 是什么?
# 论文的不足
# 论文如何讲故事
#
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12