 Learning Visual Words for Weakly-Supervised Semantic Segmentation
Learning Visual Words for Weakly-Supervised Semantic Segmentation
# Learning Visual Words for Weakly-Supervised Semantic Segmentation
# 作者:Lixiang Ru, Bo Du, Chen Wu
# 单位:WHU
# 发表:IJCAI 2021
# 01 摘要
CAM通常只识别出最具鉴别力的物体范围,这是因为网络不需要发现物体全貌来识别图像级别的标签。论文提出同时学习图像级标签以及本地的visual word 标签来处理这个问题。
用一个可学习的 codebook 来编码输入图像的feature map,为了网络能够分类编码的细粒度的visual words,生成的 CAM 应当需要覆盖更多的语义区域,除此之外,提出了混合空间金字塔池化模块(hybrid spatial pyramid pooling module),能够保留 feature map 上的局部最大值以及全局平均值,可以捕获更多的目标细节以及更少的背景,在PASCAL VOC 2012 的val set上可以达到 67.2% mIoU,test set上可以达到 67.3% mIoU
# 02 论文的目的及结论
- 用特征图上的 Visual Word 的特征来约束模型学到更多的语义区域
- 提出 HSPP 结合 GAP 和 GMP 优点
# 03 论文的方法
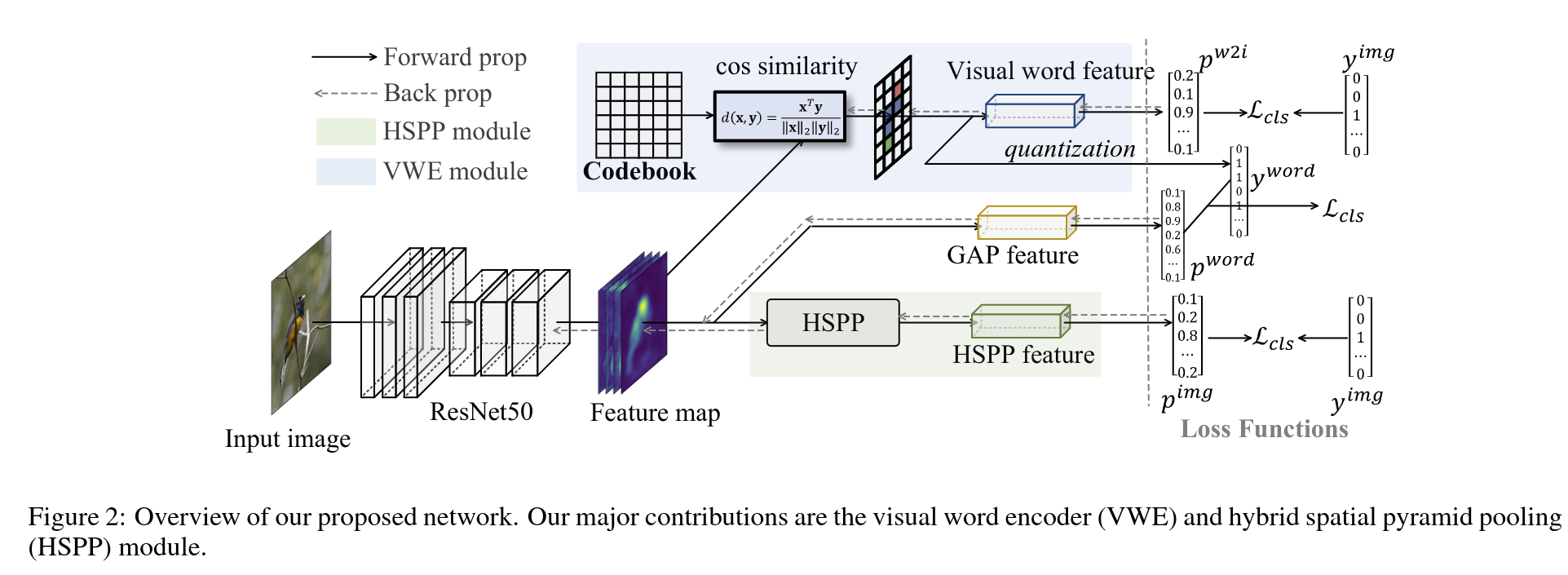
主要提出两个模块
VWE: Visual Word Encoder,编码 local visual words
HSPP: Hybrid spatial pyramid pooling layer,更好地聚合信息
# 3.1 VWE 模块
codebook 是一个 Matrix
- 是 feature map 的维度
- 是词的数量
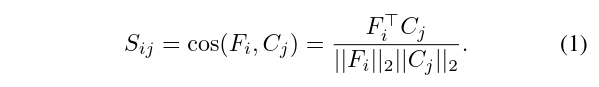
是余弦距离,代表feature map 上 位置上与 矩阵中 第 个词的相似度
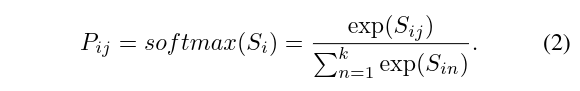
通过 softmax 做行上的归一化,来计算第 个像素属于第 个词的概率,概率最大的词即作为 的 visual word label,对于输入图像来讲,visual word label 是一个 维的向量,
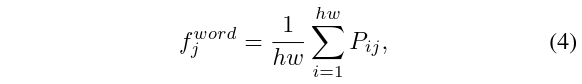
在BoVW 模型中,每个visual word 的直方图分布通过出现的频次来衡量,然而,hard quantization 的方法会引入非连续性,并被证明会使训练过程难以完成。本篇论文通过累积 上的概率来计算每个词的频率,因此,第 个词的"软频率"就是如上式所示
传统的 BoVW 模型中,codebook 通常认为是所有 visual word 的聚类中心,但在本文的模型中,visual word 的特征表示是在训练过程中在线更新的。因此,码本 也是会在线更新的。
# 3.2 HSPP 模块
为了克服 GAP 和 GMP 的缺点,提出 HSPP 聚合多尺度的局部最大值以及全局平均值
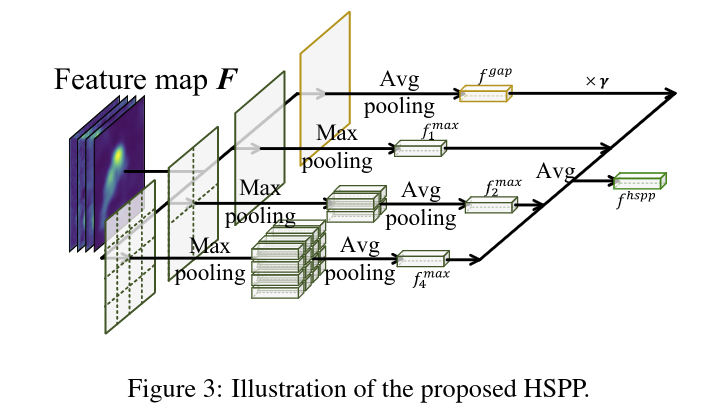
假设特征图维度是 ,按照缩放因子 分成多尺度,每一份的维度为 ,缩放因子的取值为1,2,4.
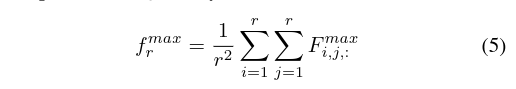
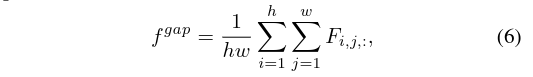
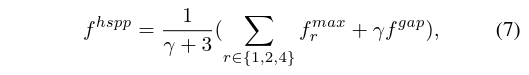
式五只能提取局部的最大响应,可能会造成目标区域的不完整,
# 3.3 损失设计
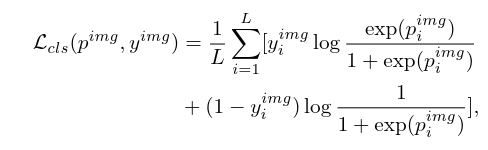
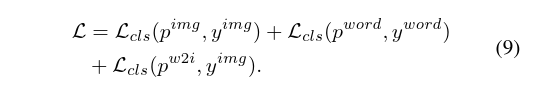
# 3.4 生成CAM
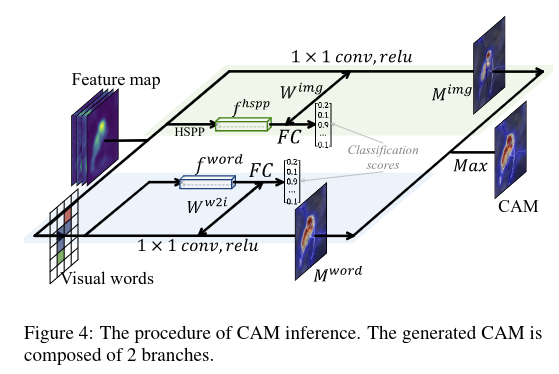
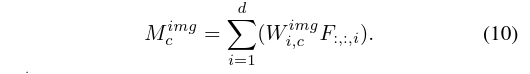
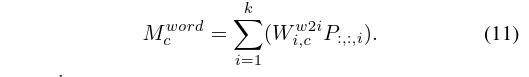
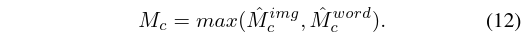
走两个分支,一个conv feature,一个word feature,最后取 max 共同生成CAM
# 04 论文的实验
将 ResNet50 用来提特征,使用 IRNet 做 CAM 的Refine,使用ResNet101 作为 backbone 的 DeepLabv2 产出最后的实验结果
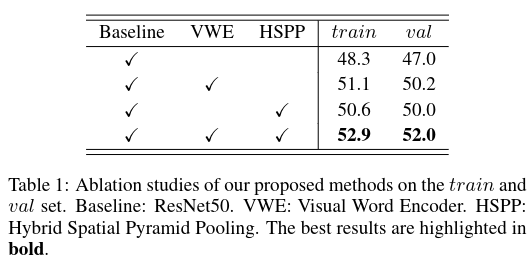

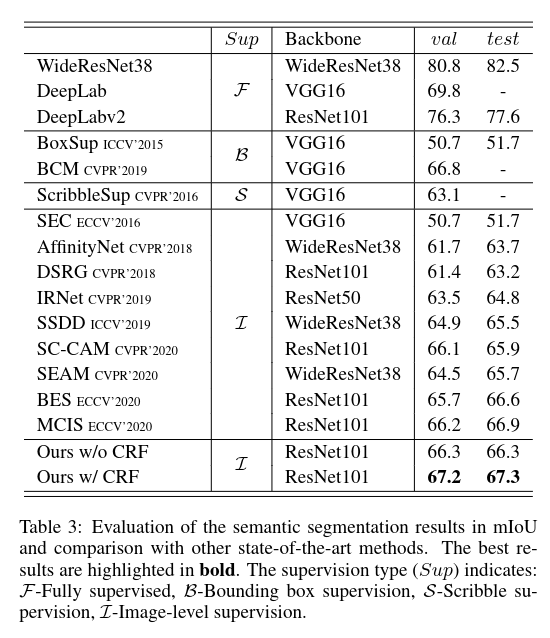
# 总结
# 论文的贡献
# 论文的不足
# 论文如何讲故事
# 参考资料
- https://www.ijcai.org/proceedings/2021/0136.pdf
- https://github.com/rulixiang/vwe
- https://lixiangru.cn/assets/files/VWE_Poster.pd
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12