 AffinityNet Learning Pixel level Semantic Affinity with Image level Supervision for Weakly Supervised Semantic Segmentation
AffinityNet Learning Pixel level Semantic Affinity with Image level Supervision for Weakly Supervised Semantic Segmentation
# Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation
# 单位:DGIST, POSTECH
# 作者:Jiwoon Ahn, Suha Kwak
# 发表:CVPR 2018
# 摘要
分割标签的不足是语义分割的主要问题,为了缓解这一问题,我们提出了一个全新的框架,给定image-level 类别标签即可生成分割标签。在这种弱监督的设置下,众所周知的是训练模型是对局部辨别的部分而不是整个物体区域进行判别。我们的解决方案是将这种局部反应传播到属于同一语义实体的附近区域。命名为 AffinityNet ,用来预测一对相邻图像坐标之间的语义亲和性,语义传播则利用AffinityNet 预测得到的 affinity 进行 Random Walk操作来实现。
更重要的是,用于训练AffinityNet的监督是由局部判别性部分分割提供的,它作为分割注释是不完整的,但对于学习小图像区域内的语义亲和力是足够的。
# 阅读
# 论文的目的及结论
# 论文的实验
# 论文的方法
方法分成两部分
- 利用给定的image-level 的标签合成pixel-level的标签
- 利用生成的分割标签训练分割模型
整个框架分为三个网络:一个网络用于计算CAMs,AffinityNet,以及一个分割模型,前两个用于生成训练图像的分割标签,最后一个利用生成的分割标签来完成语义分割任务。
# 3.1 计算CAMs
在其他弱监督方法中,CAMs 会被当做分割种子,局部显著区域,然后传播以覆盖到整个目标区域,在本论文中,CAMs 还被用作 AffinityNet 的监督信号。Follow 了 [40] 的方法来计算CAMs,该架构是一个典型的分类网络,具有全局平均池(GAP),然后是完全连接层,并通过一个具有图像级别标签的分类标准进行训练。
给定训练好的网络,groundtruth 的类别 的 CAMs 表示为 ,计算公式为
是与类别 有关的分类权重, 是指 (x,y) 处的 GAP 层前的特征向量。 被进一步归一化,使得最大响应等于 1:。对于和groundtruth 无关的类别来讲,我们都将其 置为0。该文章也计算了一个背景响应图,计算公式是
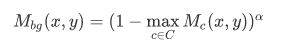

# 3.2 学习 AffinityNet
AffinityNet 旨在预测训练图像上一对相邻坐标之间的类不可知的语义亲和力。预测得到的亲和力被用于random walk 的转移概率,random walk 将 CAMs 的激活分数传播到具有相同语义的附近区域,从而显著提升了 CAMs 的质量。
为了计算效率,AffinityNet 预测一个卷积的特征图 ,一对特征向量的语义亲和度由他们之间的 距离来定义,feature 和 feature 的距离 公式如下, 表示 feature 在 feature map 上的坐标:
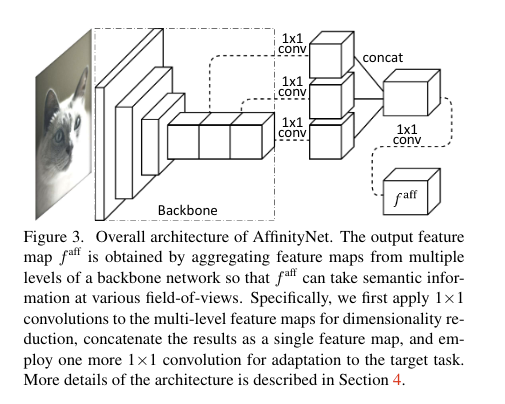
上图是AffinityNet 的整体架构,Backbone 后不同stage 的特征经过 1x1 卷积降维后 concat 到一起得到
# 3.2.1 生成语义亲和度标签
为了用 image-level 的标签训练 AffinityNet,我们利用CAMs 作为监督信号。虽然 CAMs 通常来说都不是很精确,我们发现仔细处理他们也能获得对语义相似性的可靠监督信号

基础的 idea 就是判别出那些可靠性较高的目标区域以及背景,从这些区域中采样训练样本。通过这种方式,一堆采样坐标间的语义相似性可以被较为可靠的确定。为了估计物体的置信区域,我们首先通过减少公式(2)中的 α来放大,使背景分数支配 CAMs 中物体的不重要的激活分数。在经过 dCRF 对 CAMs 做细化之后,通过收集那些目标类别的分数比其他类别及背景分数大的坐标来作为置信区域。在相反的实验设置(增大,减弱 ) ,可靠的背景区域会以同样的方式识别出来,图像剩余的区域则被认为是中立区域(neutral),结果如上图所示
现在即生成了二类的affinity label,对于每一对像素的坐标 以及 来讲,如果他们的类别相同,其affinity label 即为1,如果类别不同则为0。如果其中一个坐标是中立区域,我们就可以简单的在训练过程中忽略掉这一对点。利用这种方案使得我们能够收集相当多的成对亲和力标签,这些标签也足够可靠
# 3.2.2 AffinityNet Training
AffinityNet 通过近似二类的affinity label来训练。在训练期间由于以下两个原因只需要考虑足够相邻坐标的亲和力即可
- 由于上下文的限制,预测两个非常远坐标的语义相似度是很难的
- 为了只解决相邻的成对坐标,我们可以大大减少计算开销
所以用作训练的坐标对叫做 ,
也就是说在半径范围内的点才被用作训练,但是这还是会导致类别不平衡问题, 中类别分布明显偏向于 Positive类,而 Negative 类仅仅在对象边界附近采样,在 Positive 类别中,背景类别对的数量也明显大于物体对的数量,为了解决这个问题,文章将 分成了三个子集,将三个子集上的损失汇总起来。

如上图所示,先将 分为 和 , 再将 分为 和
- 代表 为 1 的 pair, 代表 object 的 Positive pair, 代表背景的 Positive pair
- 代表 为 0 的 pair
最终的 Loss 也分为三块,分别是 ,,,总损失为 ,值得注意的是,该损失是类别无关的,这可以使得 AffinityNet 学到更加 general 的表示用于区分目标和背景。
# 3.3 使用 AffinityNet 对 CAMs 做细化
用训好的 AffinityNet 对CAMs 做细化,AffinityNet 预测得到的局部语义相似度被转化为一个转移概率矩阵,确保random walk 可以了解图像中的语义边界,并鼓励其在这些边界内扩散激活分数。
对于输入图像,AffinityNet 生成一个卷积特征图以及式(3)所描述的语义相似度。经过计算的相似度形成一个相似度矩阵W,其对角线元素为1。 从相似度矩阵中得出的Random walk的过渡概率矩阵T如下所示:
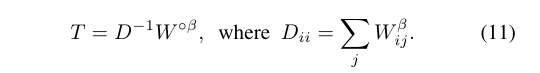
是一个比 1 大的超参数,得到原始相似度矩阵 W 的Hadamard幂,忽略掉一些相似度,得到 矩阵
对角矩阵 D 是对 矩阵 做行归一化得到的
通过矩阵 T 的Random walk,语义传播的操作是通过将 T 与 CAMs 相乘来实现的,我们迭代地进行这种传播,直到达到预定的迭代次数。

代表矩阵向量化, 代表迭代的次数,
# 论文的背景
# 总结
# 论文的贡献
# 论文的不足
# 论文如何讲故事
# 参考资料
https://arxiv.org/abs/1803.10464
https://github.com/jiwoon-ahn/psa
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12