 DMT Dynamic Mutual Training for Semi-Supervised Learning
DMT Dynamic Mutual Training for Semi-Supervised Learning
# DMT: Dynamic Mutual Training for Semi-Supervised Learning
# 作者:商汤 Jianping Shi、上交 DMCV 实验室
# 发表:arXiv 准备投 PR
# 摘要
近期的半监督学习方法将利用伪标签作为核心思想,但是伪标签并不可靠。自训练的方法依赖于单模型预测的置信度来过滤掉低置信度的伪标签,但是存在以下问题:有概率保留高置信度的带噪样本以及丢弃掉低置信度的正确样本。在这篇论文中,我们指出模型很难发现自己的错误,相反利用不同模型间的差异是定位伪标签错误的关键。从这个新角度出发,我们提出了在两个不同的模型中互训练,并利用一个动态重加权的损失函数,称作动态互训练(DMT),通过比较两种不同模型的预测以动态分配训练中的权重,来量化模型间的分歧,较大的分歧表示较高概率的错误,并对应较低的损失值,实验证明 DMT 能够在图像分类和图像分割上都能达到 SOTA 的结果。
# 阅读
# 论文的目的及结论
想通过比较两种不同模型的预测来动态分配训练中样本的权重,最终能够在图像分类和图像分割上都能达到 SOTA 的结果。
# 论文的实验
对于图像分类任务,在 CIFAR-10 上做了实验。对于语义分割任务,在 PASCAL VOC 2012 和 Cityscapes 数据及上做了实验。由于 DMT 在迭代框架中能够有更好的性能以及快速的收敛,所有的 DMT 实验都默认 5 次迭代,在单张 RTX2080 Ti GPU 上做实验,全监督的学习结果被称作 Oracle,作为半监督学习结果的上限。然而由于全监督的标注中也有噪声,我们的 DMT 方法可以超过全监督方法得到的性能。
# 1、超参数调整
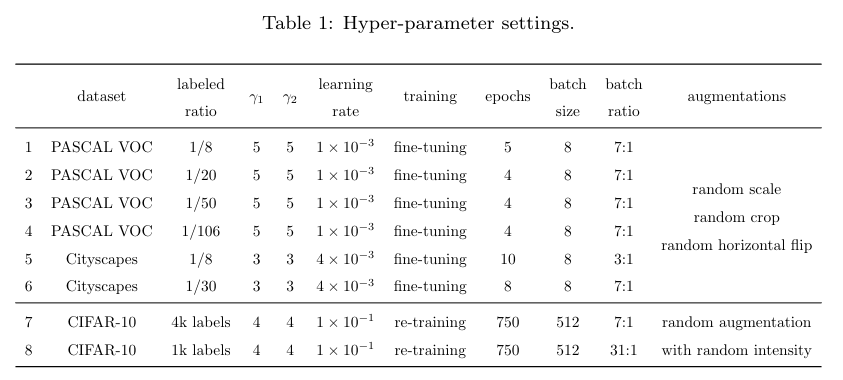
为了避免太多的超参数调整,作者设置 ,我们有确定的比例(例如 labeled:unlabeled = 1:7),更多的细节在上述的表一中都列出来
# 图像分类
**训练阶段:**网络架构使用 MixMatch 中的设置 WideResNet-28-2 作为 backbone。每个 DMT 迭代是 750 epochs,学习率为 0.1,权重衰减为 ,动量设置为 0.9,余弦学习率调整器以及 512 的batch size,与 [26] 的课程学习实验设置相同,为了公平比较,作者并未使用 [32] 中提出的 SWA 技巧。数据增强是 带有 Cutout 的 RandAugment[33],在每一个 step 中随机选择一种随机强度的增强操作以避免超参数的调整,并且使用 Mixup来应用动态权重
测试阶段:五次测试的平均,指数移动平均网络(follow 了 MixMatch[11])
# 语义分割
**训练阶段:**follow 了 [8, 12] 的方法使用 DeepLab-v2 ResNet-101 作为 backbone,没有多尺度融合以及 CRF 的后处理,作者的方法性能能够显著地超过以前方法的性能。由于使用了fine-tuning,分割任务的每个 DMT 迭代需要更少的训练 step,使用 SGD 优化器 (Momentum 为 0.9,lr schedule 为 poly, batch size 为 8),数据增强包括随机缩放,随机裁剪以及随机翻转,训练的尺度为 (PASCAL VOC 2012) 以及 (Cityscapes)
测试阶段: 三次测试的平均
# 2、性能的比较
# 图像分类(CIFAR-10 数据集)
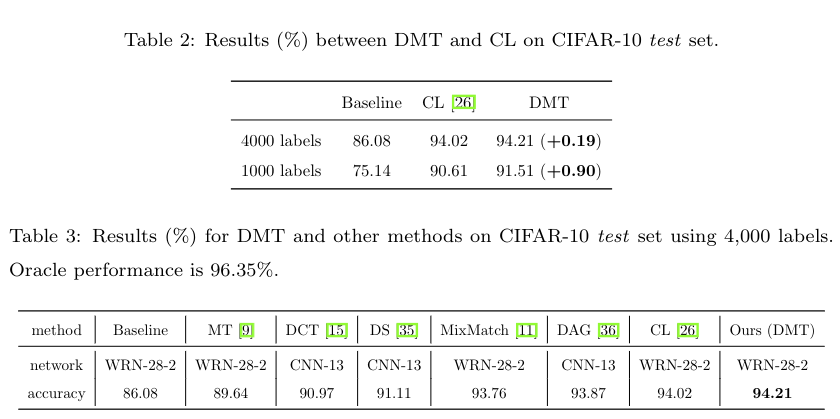
和 Mean Teacher(MT) [9],Curriculum Labeling(CL)[26],Deep Co-Training (DCT)[15],Dual Student(DS)[35],MixMatch[11],DAG[36] 方法进行比较,在 1k 和 4k 的标签划分下都进行了比较。带有 mixup 以及 其他数据增强的全监督性能作为Baseline,Baseline,CL,DMT 使用同一套 codebase 来实现,其他的方法都从原始论文中获取
# 语义分割(PASCAL VOC 2012 以及 Cityscapes)
PASCAL VOC 2012
比较方法有:基于一致性的 MT-Seg[9],Mean Teacher 使用了 CutMix 数据增强;基于特征层面一致性的 CCT 算法[37];将孪生的学生用于语义分割的辅助缺陷检测器(GCT)[38];基于 GAN 的方法[8],与训练了一个分类器用来选择伪标签;以及混合方法 s4GAN + MLMT [12] 使用额外的分类分支为 [8] 添加了一致性的正则化约束。
实验设置:将数据集做四个划分:1/106(100个标签)、1/50、1/20、1/8。我们不使用超过 1/8 的数据量对sota 的方法的性能超越不多。在监督子集上的有监督算法的性能称作 Baseline . MT-Seg、CCT、GCT的性能是在GCT 的 (codebase)[https://github.com/ZHKKKe/PixelSSL/tree/master/task/sseg] 上重新评估过。其他的性能使用原始论文中得到的。所有的方法都是使用与我们相同的网络架构进行评估的,CCT使用了略优秀的架构 PSPNet-ResNet-101 [39] 进行评估。
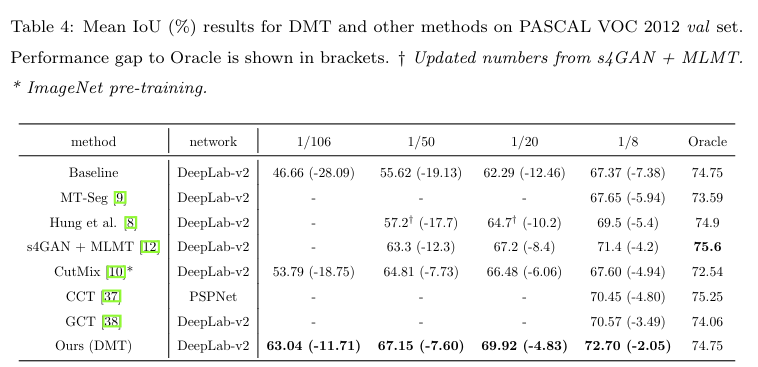
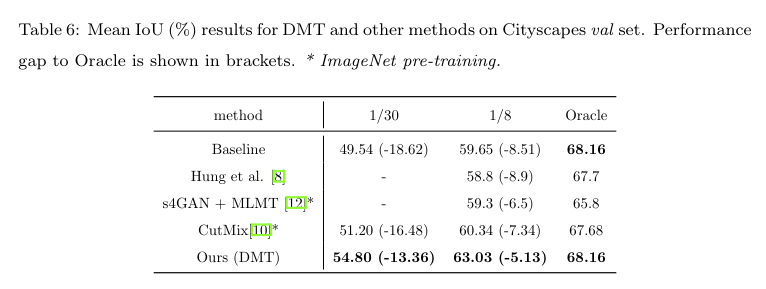
在表 4 中,DMT 超过了现有的很多方法,然而由于有些方法有 GAN 网络以及额外的网络分支,其结果和Baseline 有所不同。因此作者展示了和 Oracal 之间的算法性能差异,我们的方法性能最优异,然后能够在不同的数据集上都有稳定的性能。
与 human supervision 相比较,原始的PASCAL VOC 2012 有1464张训练图像,称作train set ,还有广泛使用的 10582 张训练集称作 trainaug (SBD)[30]。SBD数据集使用相同的图像集合,但其利用亚马逊的AMT提供了更多的标注信息。然而不专业的标注人员会造成带噪的边界,所以 trainaug 数据集会存在的很多 Coarse 的边界,存在更差的标签质量。所以我们使用 train 数据集作为已标注的子集,使用SBD 数据集中的 9118 张图像作为未标注的子集,然后利用 DMT 在其上做实验。
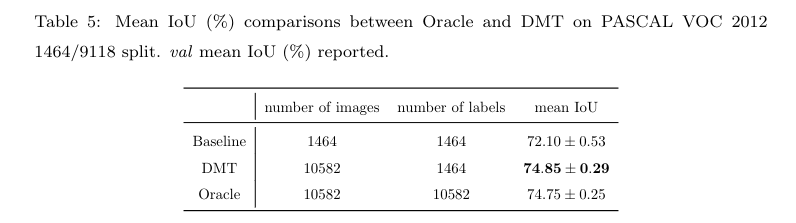
在图五中展示的那样,DMT算法可以超过 Oracal 的性能,这个结果展示了 DMT 能够产生更好的标签质量,不过由于DMT 需要用到两个模型,所以其速度大约是一个模型训练代价的两倍。
Cityscapes
Cityscapes 具有复杂的街道场景,半监督的方法较少涉足。参考 PASCAL VOC 2012 数据集的设置,来评估每个方在 1/30(100 labels)、1/8 的splits,所有实验的性能数据都从原始论文中获得
# 3、消融实验
对五个方法做了消融实验:
- Online ST:以固定的置信度阈值0.9 执行 online self-training 20个epochs
- CBST:[13] 迭代式的类平衡的自训练算法,类似于CL [26] 算法的类平衡版本
- DST:类似于DMT,单其只用一个模型来提供伪标签
- DMT-Naive:直接对 loss 进行加权,而未对三类进行区分(未使用dynamic loss)
- DMT-Flip:因为伪标签可能不正确,而不是直接把损失设置为0,我们将伪标签翻转为当前模型的预测,平切将损失重加权为 ,鉴于伪标签被翻转,作为对模型间分歧的估计
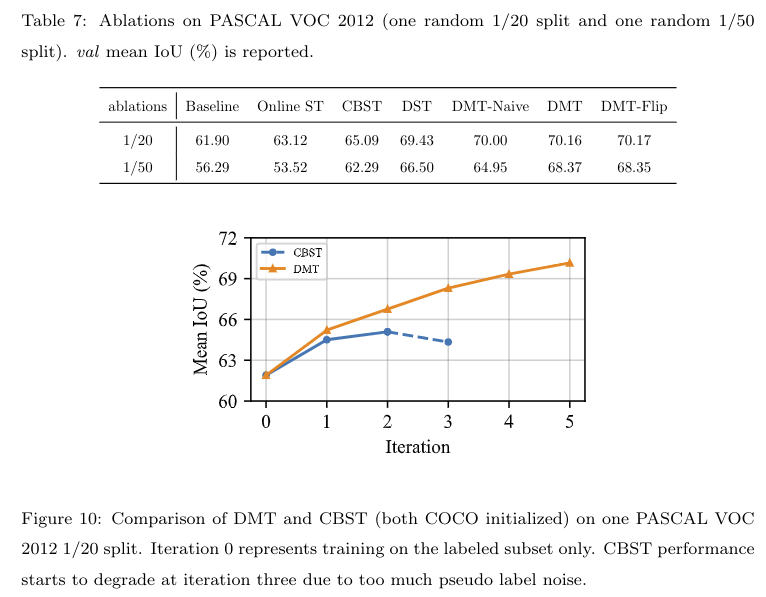
- Online ST 在标签极度稀少的情况下,它的性能甚至比 Baseline 更差,
- CBST 只进行自训练,但没有考虑伪标签的噪声,所以其在iteration = 3的时候性能增长就停止了,伪标签噪声组织了 CBST 的性能进一步提升
- DST 缺乏动态的加权,其性能会较弱
- DMT-Naive 较为简单,其可以整合模型间的分歧,当标签噪声严重时(1/50),其性能会大大的降低
- DMT-Flip 比 DMT 更加复杂,但其性能与 DMT 类似。我们认为通过翻转标签,有些类似于在线自训练的过程,
# 论文的方法
# 4.1 Dynamic Mutual Training(动态互学习)
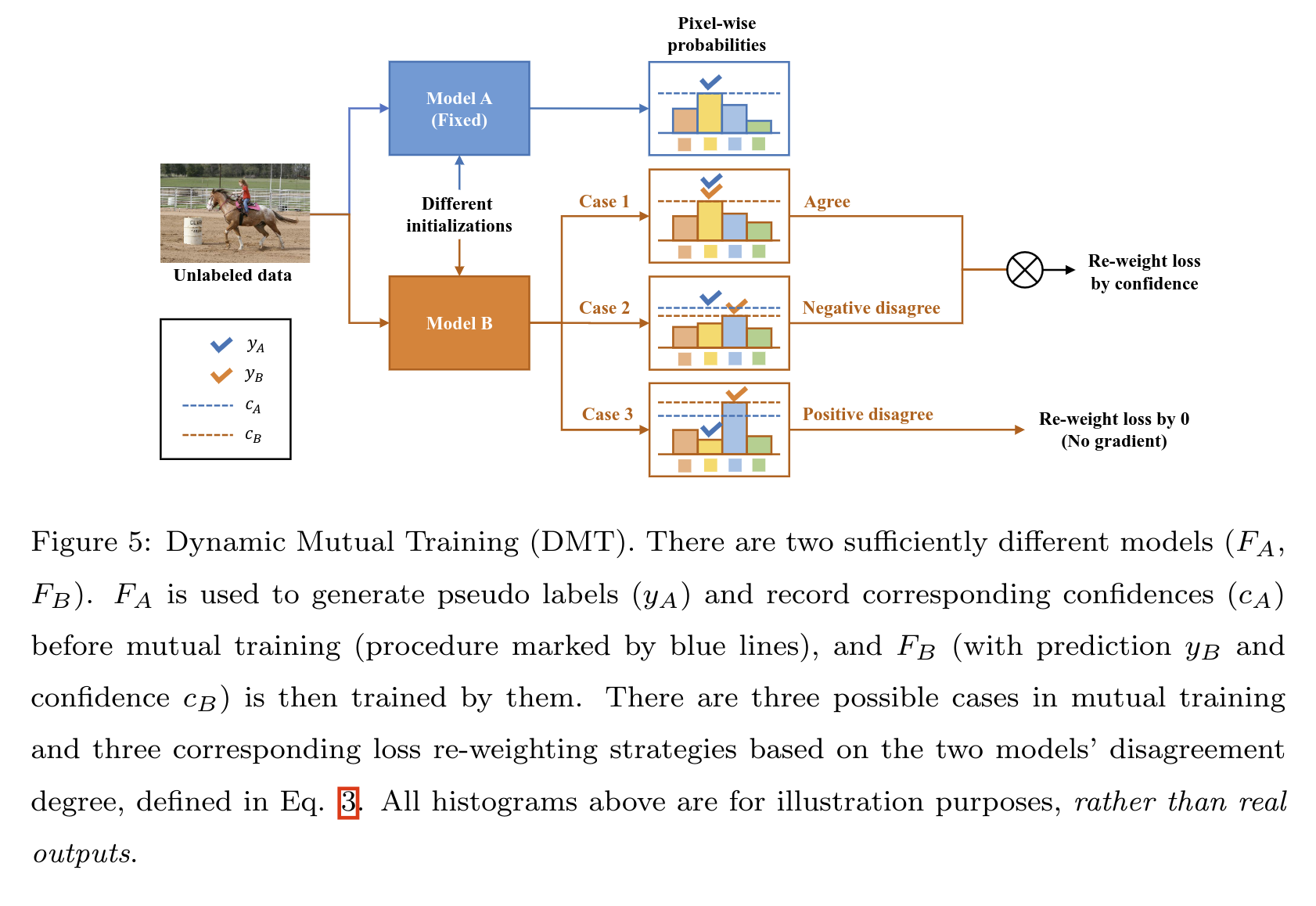
我们提出了动态互学习方法,来量化模型的歧义并且确保噪声鲁棒的训练,上图展示了整体框架。首先,在已标注的子集上训练两个不同的模型 以及 ,利用两种不同的初始化或者样本。然后一个模型,例如 固定并且产生未标注子集上的伪标签以及置信度,对于另一个模型 来讲,在所有的数据(使用已标注数据集以及未标注数据的伪标签)上使用动态加权的交叉熵进行 finetune, 可以以同一种方式训练
4.1.1 动态损失

以图像分类问题为例,用 以及 代表已标注以及未标注样本,定义 生成的伪标签为 ,带有置信度为 ,定义 生成的伪标签为 ,带有置信度为 。以上是生成权重以及计算损失的公式,
- 当 等于 时,权重为 ,满足该条件的样本称作 agreement
- 当 不等于 且时,权重为 ,满足该条件的样本被称作Negetive disagreement,即是 与 的预测有分歧,但是 的置信度会高一些
- 当 不等于 且时,权重为 0,满足该条件的样本被称作Positive disagreement,即是 与 的预测有分歧,但是 的置信度会高一些
在 case1 和 case2情况下,使用当前模型预测的概率 作为权重,来量化模型的分歧。例如,一个高的概率意味着 和 拥有更强的共识,在 case3 的情况下,我们将动态权重设置为 0 因为其伪标签可能完全不正确。
动态权重有两个超参数 以及 ,更高的 值会放大置信度的影响,更高的 值强调了熵的最小化,更高的 值强调了更多的互学习。高 值通常有利于高噪声的场景中,或者是为了保持更大的模型间分歧。对于语义分割问题来讲, 代表了一个像素级别的权重图,加权策略保持一直并且应用到每个像素上。
作者解释了为什么要分情况来设置权重,其实直接使用 作为权重也是可以的,但是作者观察到,再严重的伪标签噪声下,这种过于简单的方法效果并不好,另外动态损失的其他设计也为带来明显的性能改善(可以看实验部分的消融实验)
4.1.2 初始化分歧
CIFAR-10 这种简单任务上,直接使用不同的随机初始化参数即可引入模型分歧。然而,对于需要使用预训练模型的模型(例如语义分割任务)来讲,会通过差异最大化采样来引入模型分歧
# 4.2 迭代框架
受到课程学习、无监督域适应语义分割等方法的启发,DMT 是一个迭代式的框架,来获得更好的性能
4.2.1 图像分类

我们首先在已标注子集上训练,每次从未标注子集上选择最高置信度的一批伪标签,然后重新训练一个随机初始化的模型,与 Curriculum Labeling[26] 论文类似。上图是该算法的伪代码,在模型从零重新训练的早期阶段会提供一些有用的信息,因此我们受到[9]的启发使用了一个类似 sigmoid 函数,总的来说,总的训练step是 ,在第 个 step,
4.2.2 语义分割

在语义分割任务中,有一些类别是比另外一些类别容易学的,CBST[13] 提出了一个迭代式自训练框架,在每一轮使用每个类别 最高置信度的伪标签。并且与图像分类任务不同的是,图像分割依赖预训练权重来加速拟合,受到CBST的启发,使用两个模型。
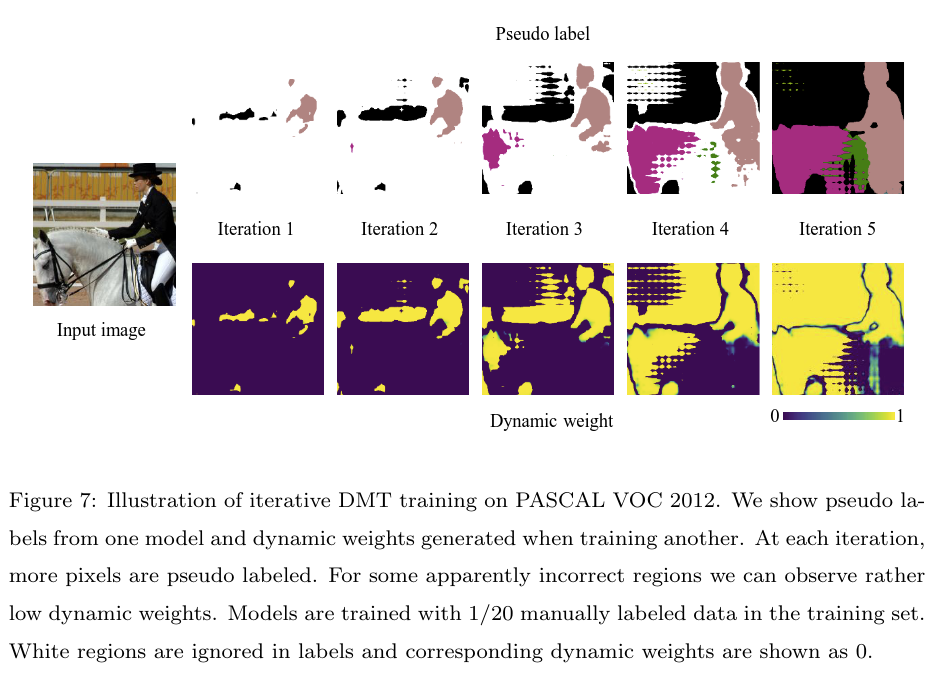
在这种设置中,两个模型互相平等地进行训练,模型间的分歧被更直接地利用,上图是DMT在PASCAL VOC 2012数据集上的动态权重图。CBST没有靠排序来选择最可靠的伪标签,其按照类别定义阈值,将置信度超过1的像素被选中训练。大多数场景中,和直接排序相似,但是在极端情况下,预测的类别可能会改变。
# 论文的背景
# 总结
# 论文的贡献
DMT 提出了一种方法,使用两个模型对伪标签生成动态权重。对样本划分了三种情况给予不同的权重,以迭代式的方法将伪标签 Refine 到越来越好,并且生成像素级的权重促进模型学习。
# 论文的不足
# 论文如何讲故事
# 参考资料
https://arxiv.org/abs/2004.08514
https://github.com/voldemortX/DST-CBC
- 02
- README 美化05-20
- 03
- 常见 Tricks 代码片段05-12